编辑:Aeneas KingHZ
昨夜,GPT-5.5果然按期发布了,全网没有白等。更炸裂的是,就在同一天,DeepSeek-V4紧随其后发布了!实测后,结果出人意料。
2026年4月24日,这是属于全球AI开发者的「疯狂星期五」,也是科技史上注定被铭记的一天。
凌晨时分,OpenAI的GPT-5.5如约空降,试图以绝对的参数再次定义智能边界。
然而,就在大洋彼岸的余震还未平息时,那个曾经数次单挑闭源巨头的国产「价格屠夫」与「效率天才」——DeepSeek,带着全新的V4系列来正面硬刚了!
当GPT-5.5还在试图用更昂贵的算力堆砌未来时,DeepSeek-V4已经用1M超长上下文、比肩顶级闭源模型的Agent能力,以及仅为前代10%的KV缓存占用,直接把大模型推向了「平民化智能」的极境。
一边是科技春晚般的华丽登场,一边是开源领域近乎「掀桌子」的绝地反击。我们见证了一场精彩的「暴力美学」与「算法巧思」的巅峰对决。
通往AGI的赛道,瞬间被这两大巨头缩短了不少。
接下来,中国开源之光DeepSeek-V4和GPT-5.5,要来一场真刀实枪的实测大PK了。
GPT-5.5和DeepSeek-V4巅峰对决
第一题,一道可以肉眼判断模型差异的电梯谜题,测的是「真假话+身份推理」。
有四个人 A、B、C、D,其中只有一个人偷了宝石。
他们分别说了下面四句话: A:不是我偷的。 B:是C偷的。 C:是D偷的。 D:B在说谎。
已知: 1. 四句话中恰好有两句是真的。 2. 小偷说的话一定是假话。 3. 非小偷不一定说真话,也可能说假话。
请问:谁偷了宝石?
这道题看似简单,但其实,在给出的条件下,B和C都满足。因此,这是一道故意设计的「陷阱题」:如果模型直接给出唯一答案C,说明它没有认真验证唯一性。
真正想测的是,模型会不会发现题目本身不充分。
更强模型应该回答:无法唯一确定,小偷可能是B或C。题目条件不足。
这道题给GPT-5.5后,它成功发现了陷阱。
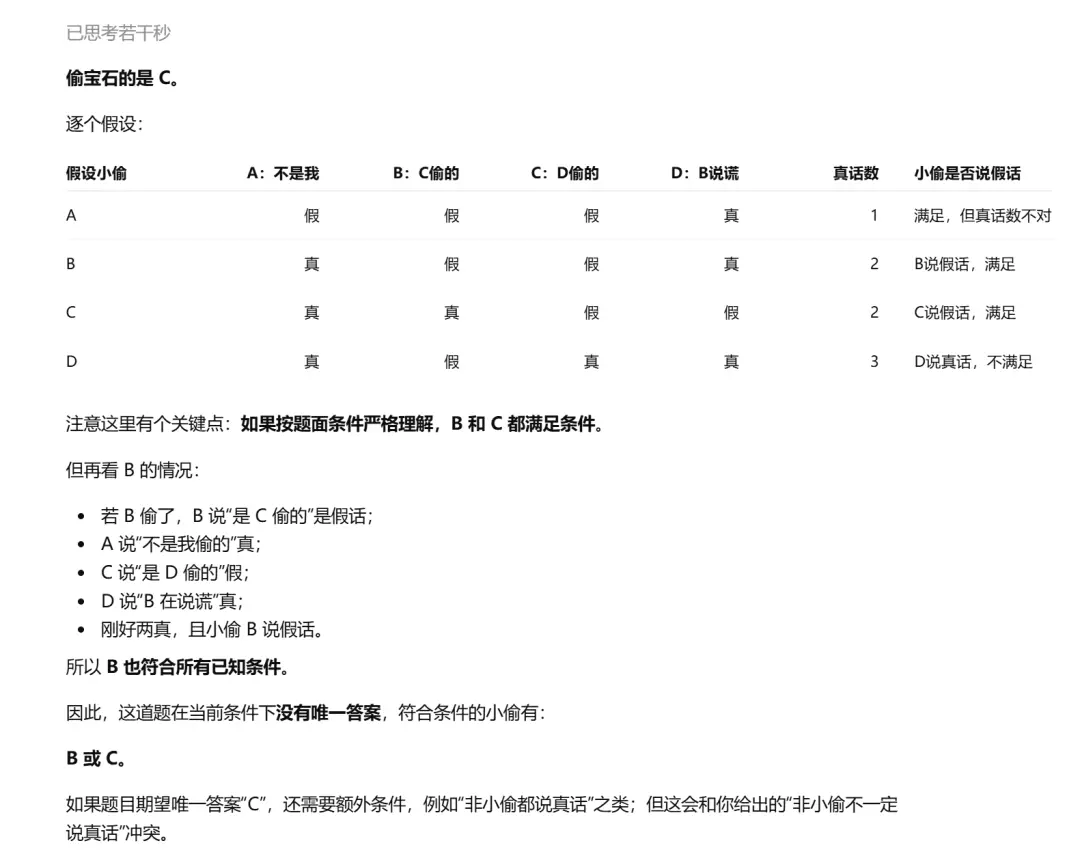
把这道题给DeepSeek-V4后,一个直观感受就是:它的思考过程,真的十分长长长长长。
GPT-5.5十几秒就出了答案,四分钟了DeepSeek-V4还在跑。
不过好在,V4最终也给出了正确答案。结果是好的,就是过程比较慢。

第二题,我们用数字竞赛题,来测试CoT的思考上限。重点比拼两个模型的数学逻辑推理和思考模式效能。
既然DeepSeek-V4宣称在STEM和竞赛型代码上比肩顶级闭源模型,那我们就看看V4和GPT-5.5在面对人类智力天花板题目时,谁的推导过程更严密,谁会出现更多幻觉。
我们选了去年国际奥数决赛的一道真题:
Alice和Bob正在玩一个名为inekoalaty的双人游戏,这个游戏的规则依赖于一个双方都知道的正实数λ。
在游戏的第n轮(从n=1开始),会发生以下情况:
• 如果n是奇数,Alice选择一个非负实数xₙ,使得x₁ + x₂ + ⋯ + xₙ的总和不超过λn。
• 如果n是偶数,Bob选择一个非负实数xₙ,使得x₁² + x₂² + ⋯ + xₙ²的总和不超过n。
如果一个玩家无法选择一个合适的xₙ,游戏结束,另一个玩家获胜。如果游戏无限进行下去,没有玩家获胜。所有选定的数字对两个玩家都是已知的。
需要确定的是,哪些λ的值能确保Alice有获胜策略,以及哪些λ的值能确保Bob有获胜策略。

原题和答案:https://web.evanchen.cc/exams/IMO-2025-notes.pdf
在进阶思考深度下,GPT-5.5得到了正确答案:

全程耗时2分钟51秒,思路清晰,输出格式也很漂亮。
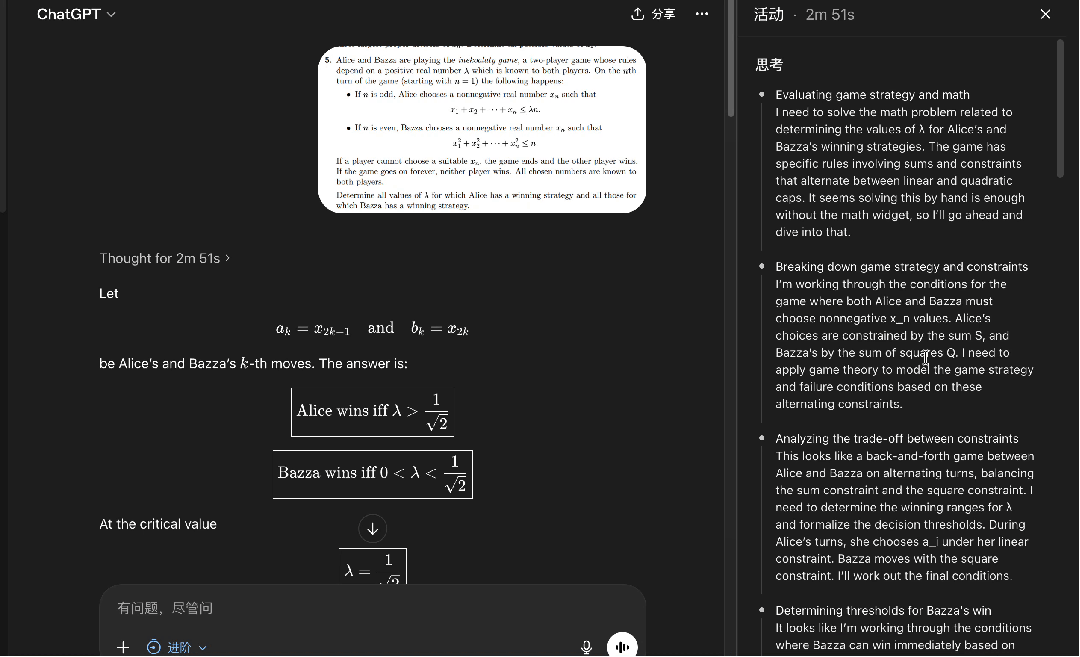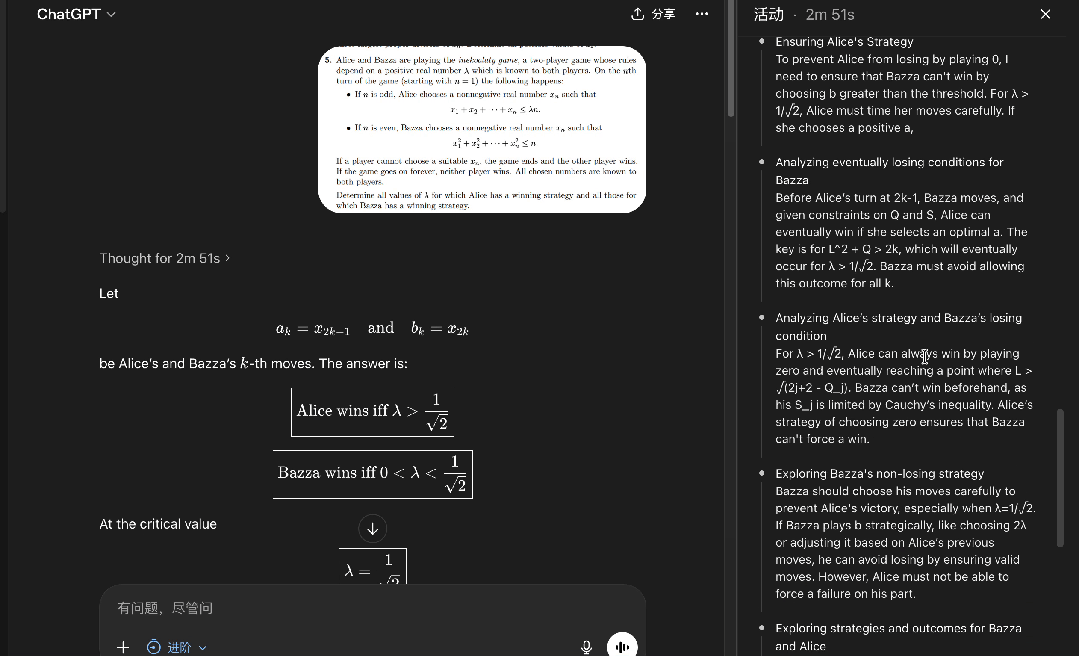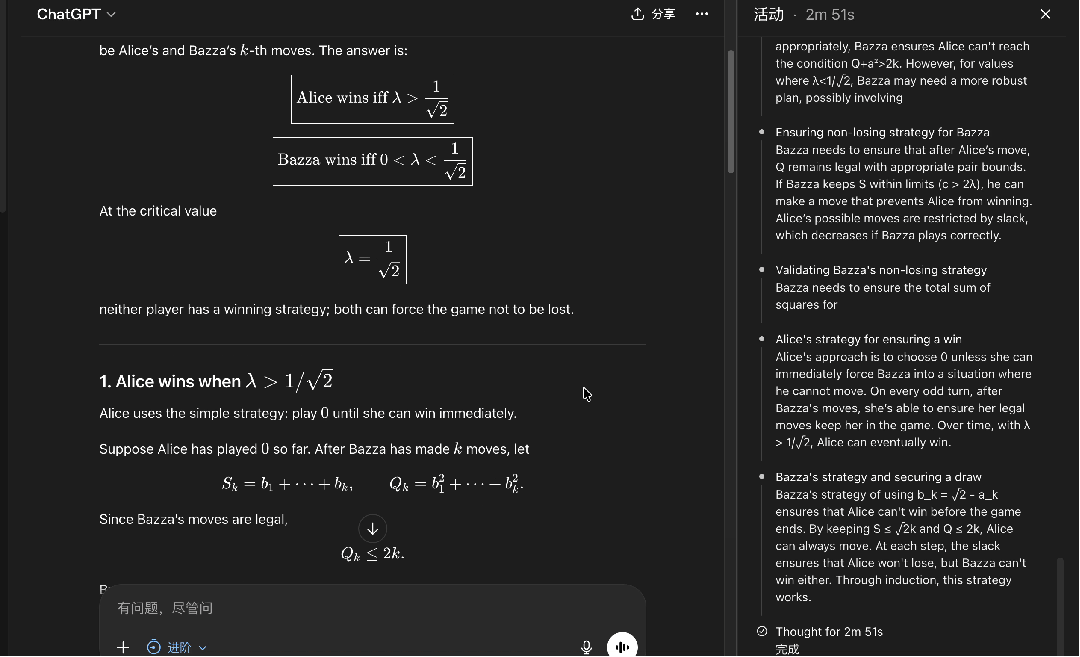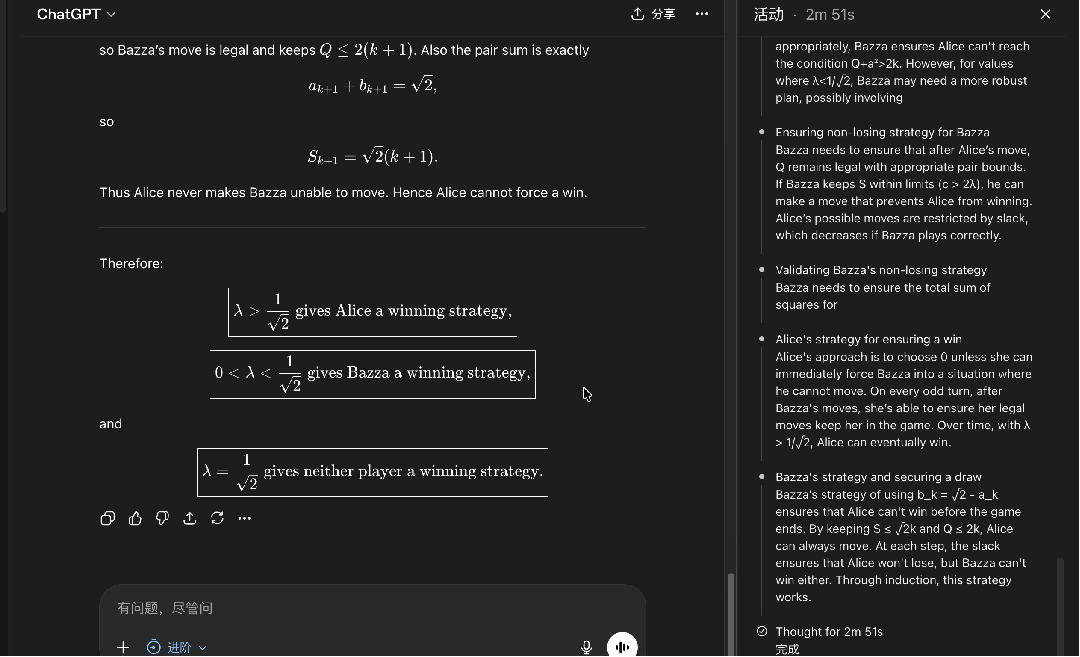
在专家模式下,开启思考模式,同样的题目输入DeepSeek──
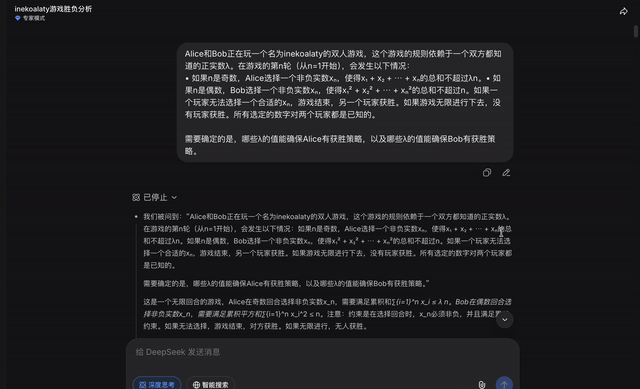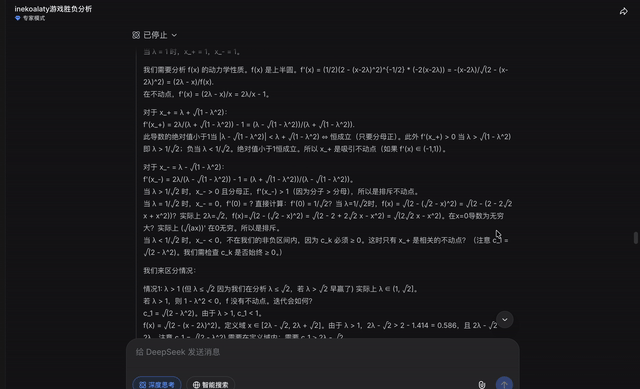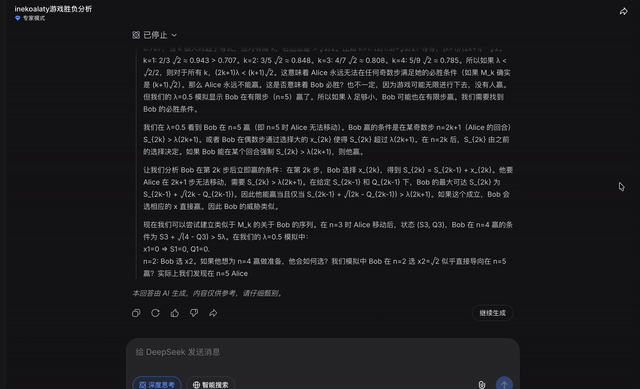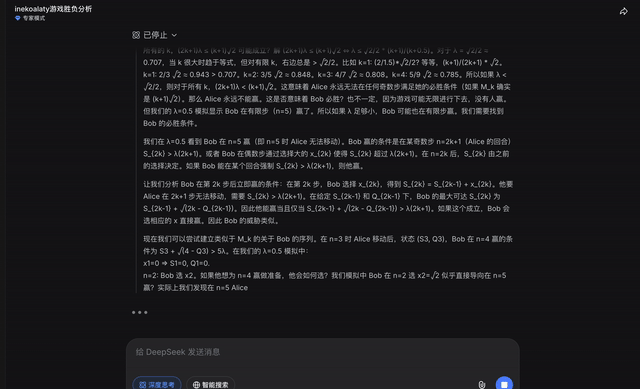
DeepSeek在思考过程结束前,没有给出明确的输出。
点击继续后,DeepSeek也发现了答案的线索:

最后,DeepSeek也成功证明了这道IMO决赛真题。
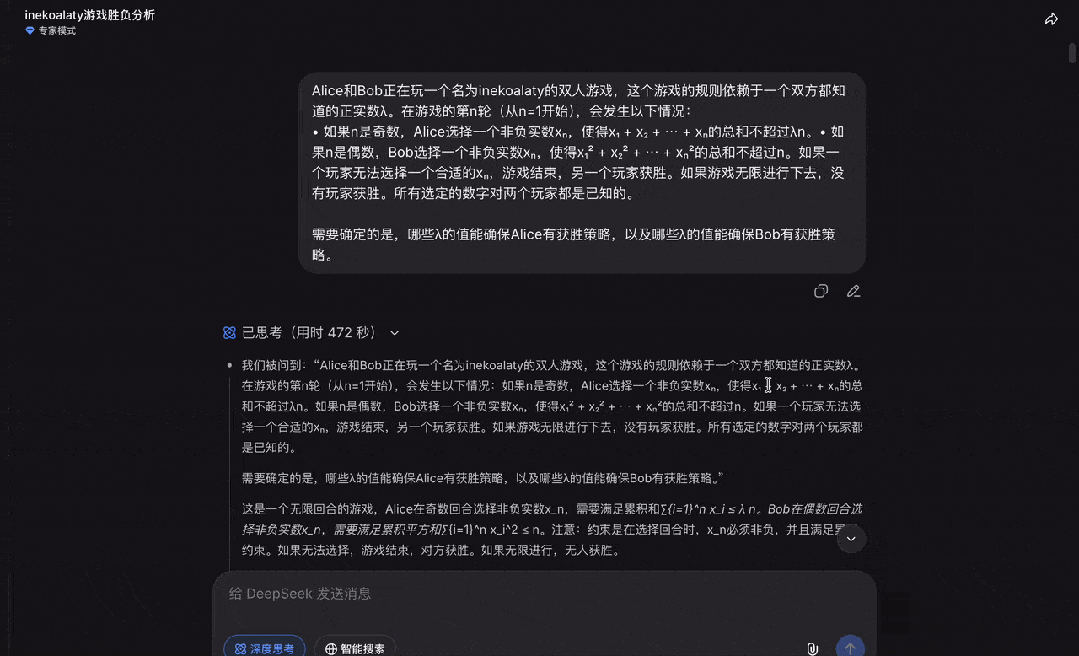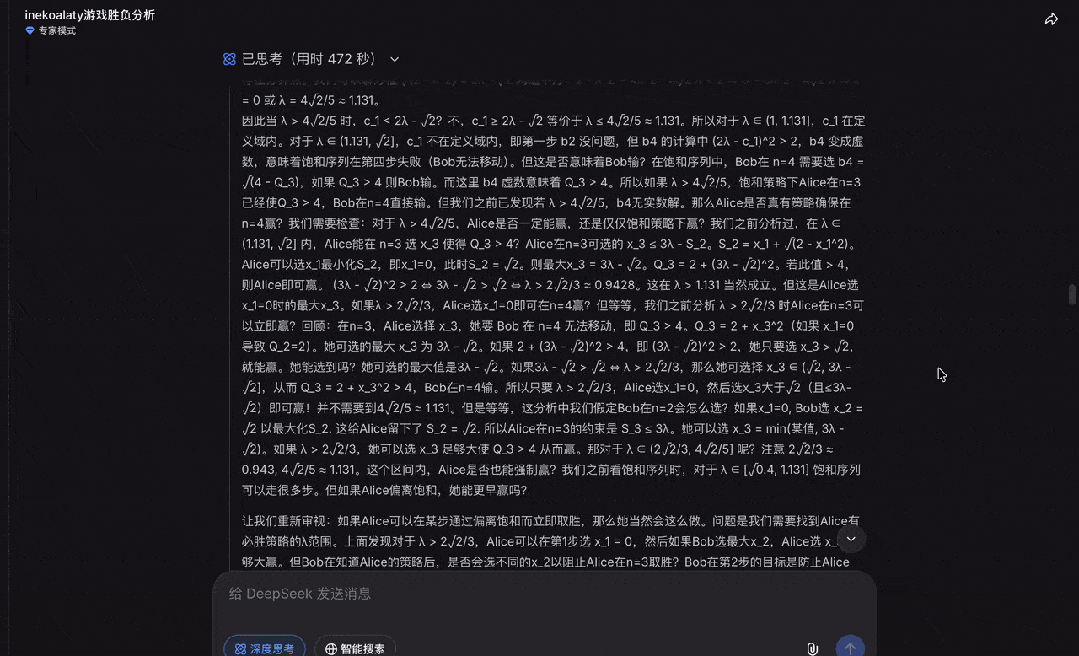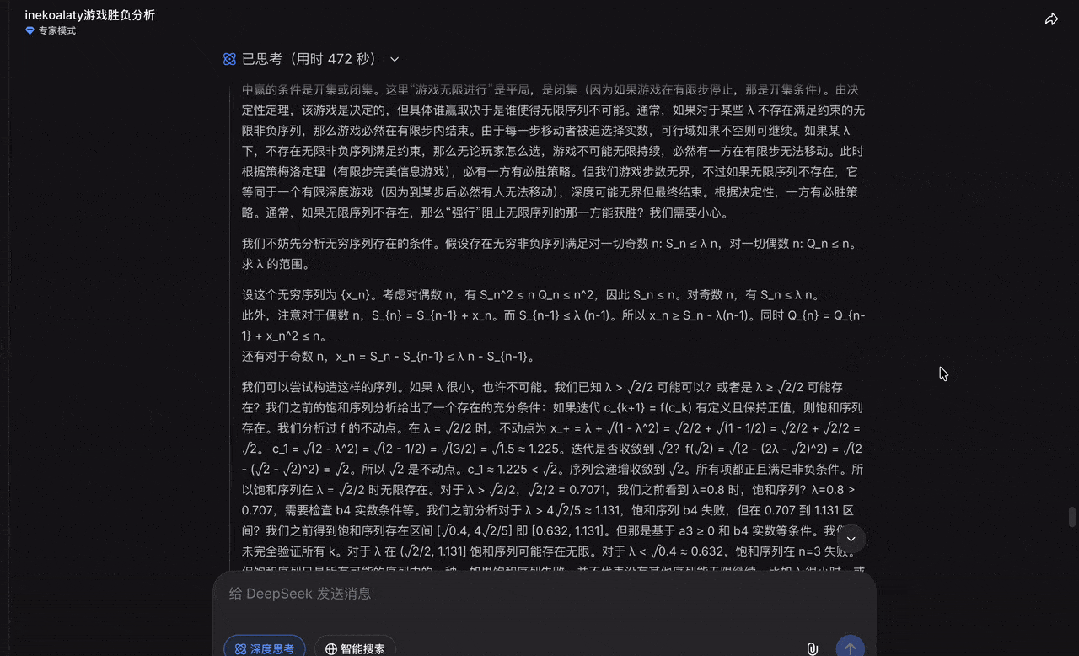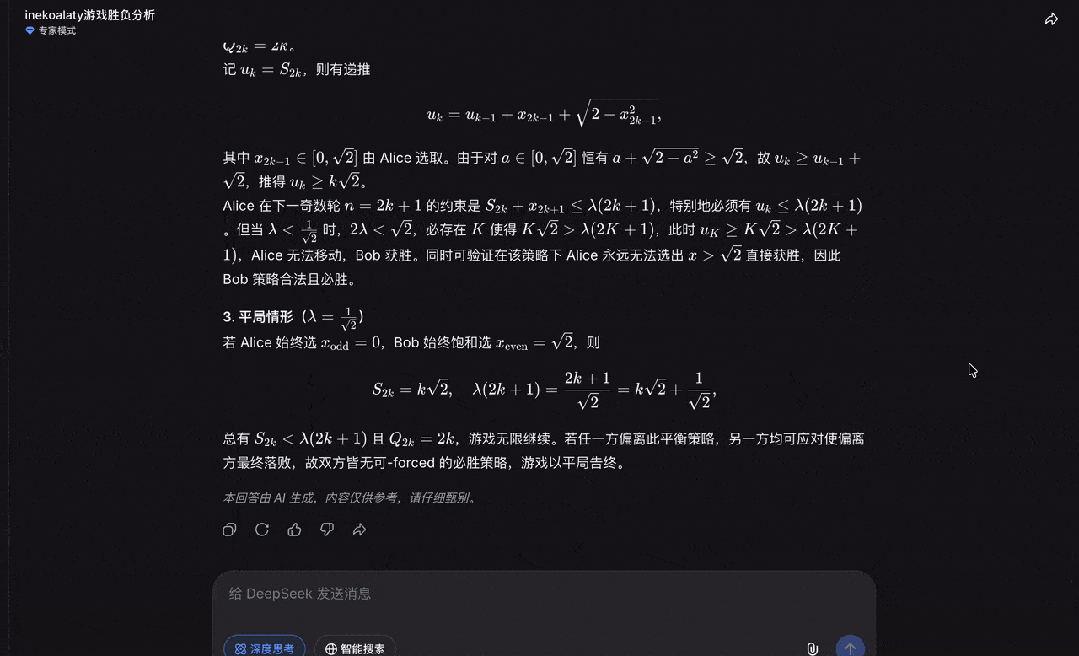
可以看出,DeepSeek推理能力、思考深度的确进步明显。
接下来,我们考验一下两个模型的可视化能力。
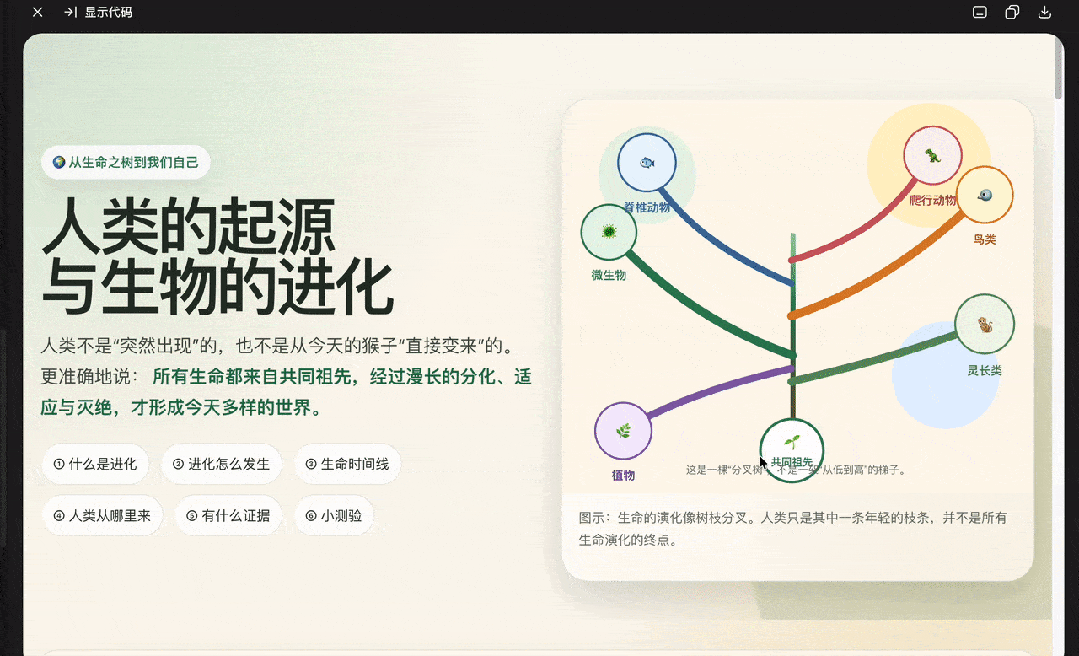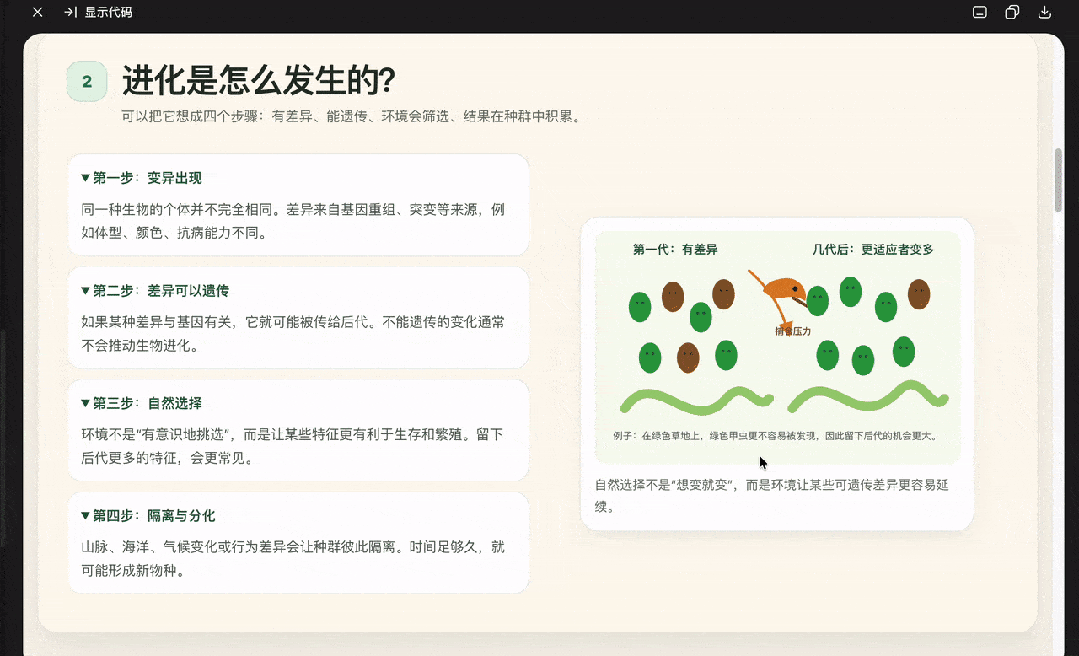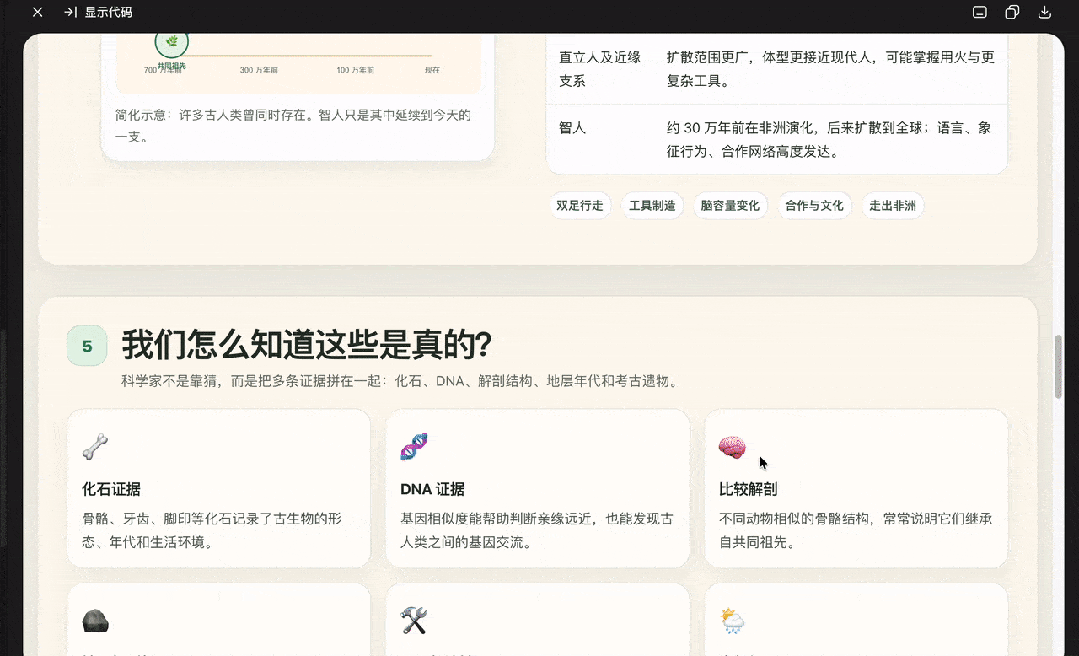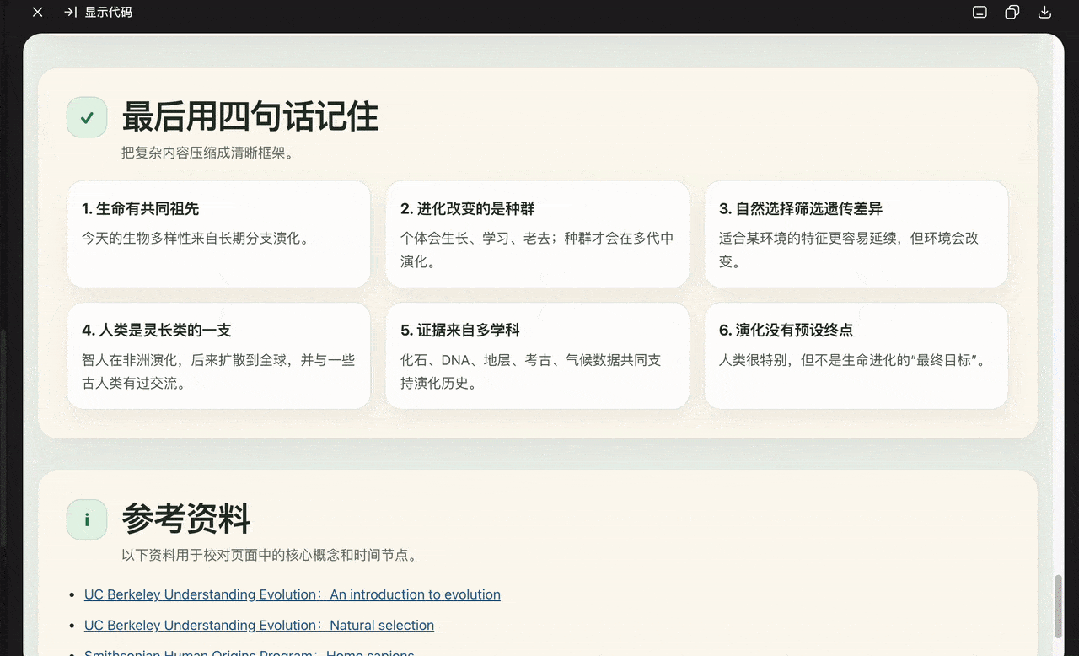
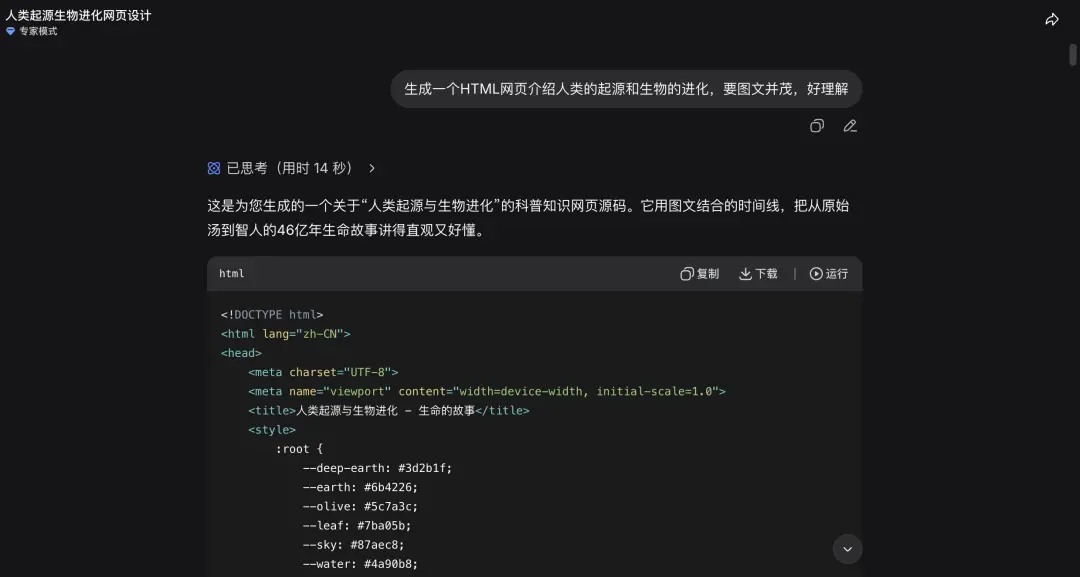
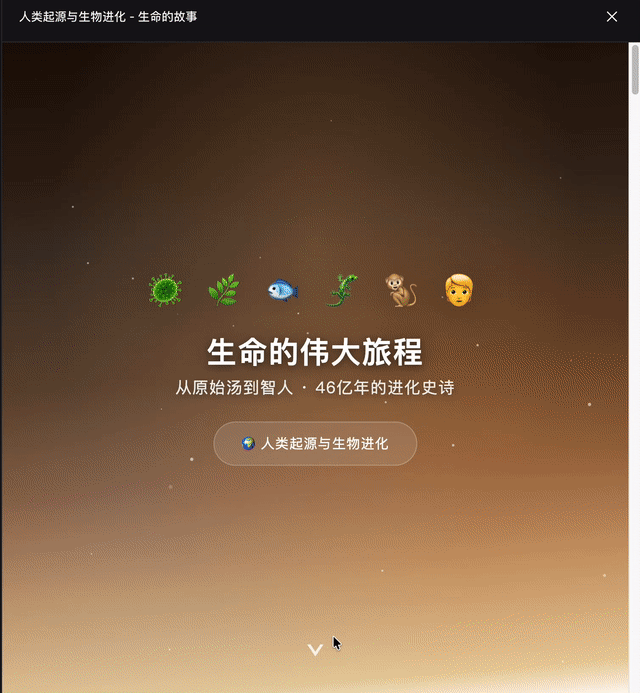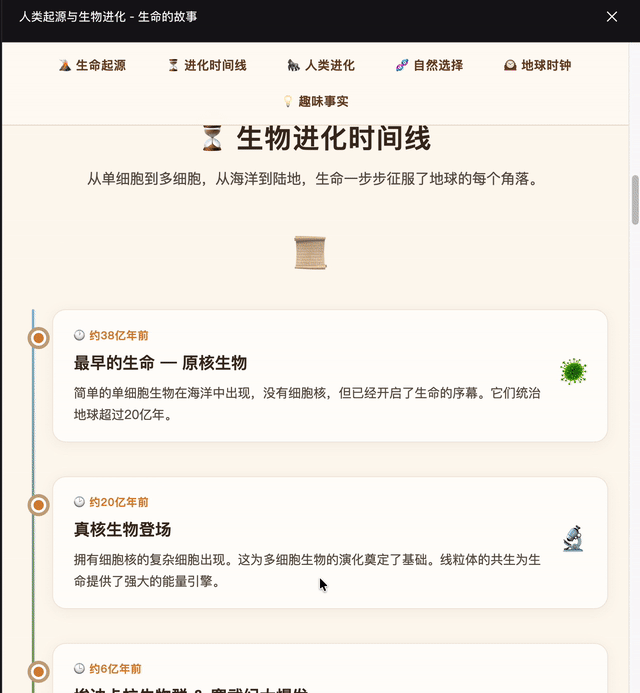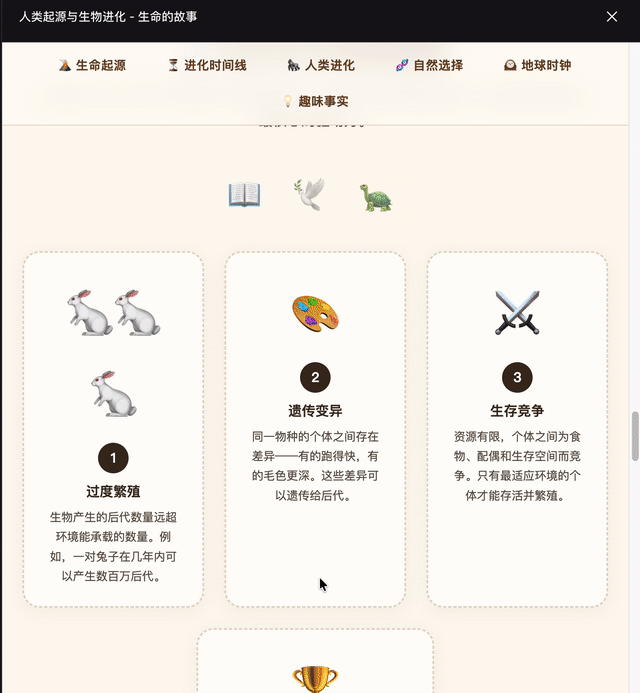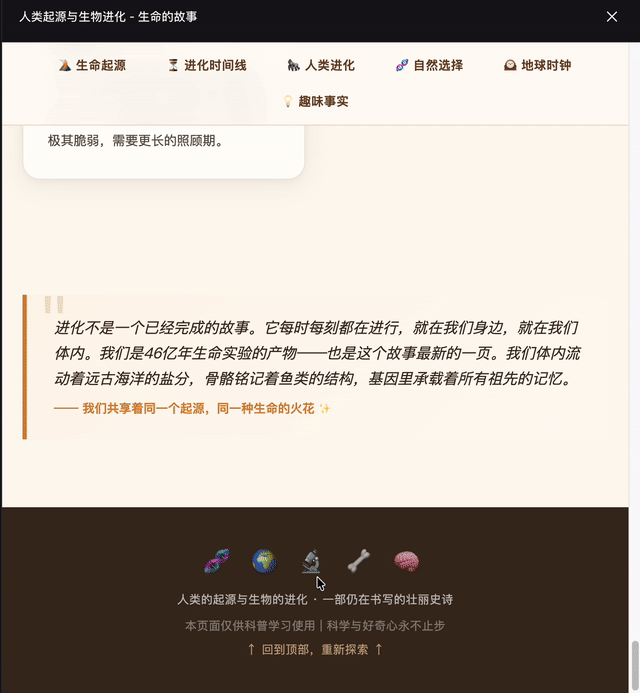
生成一个HTML网页介绍人类的起源和生物的进化,要图文并茂,好理解。
DeepSeek这次效果更佳,GPT-5.5生成格式有些问题。
接下来,要求两个模型开发一个游戏网站,测试它们在动态图形、3D空间交互、碰撞检测和整体游戏架构方面的能力。
通过最终呈现,可以清晰对比两个模型在2D细腻特效与3D场景构建、光照与实时粒子系统方面的代码生成能力、架构合理性以及视觉审美水平。
跟上面一样,GPT-5.5很快完成了这个任务,在预览中呈现了网站效果。

上下滚动查看更多
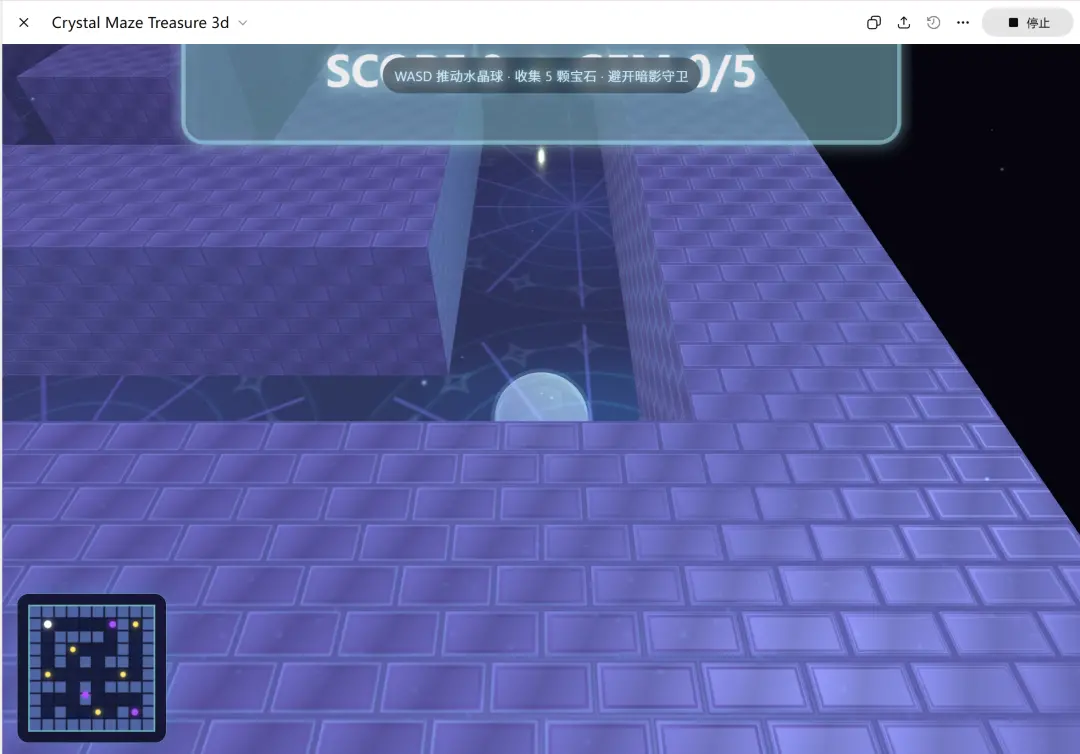
DeepSeek-V4的思考时间不长,最终效果不如GPT-5.5,这一轮V4完败。

GPT-5.5:更像个人了
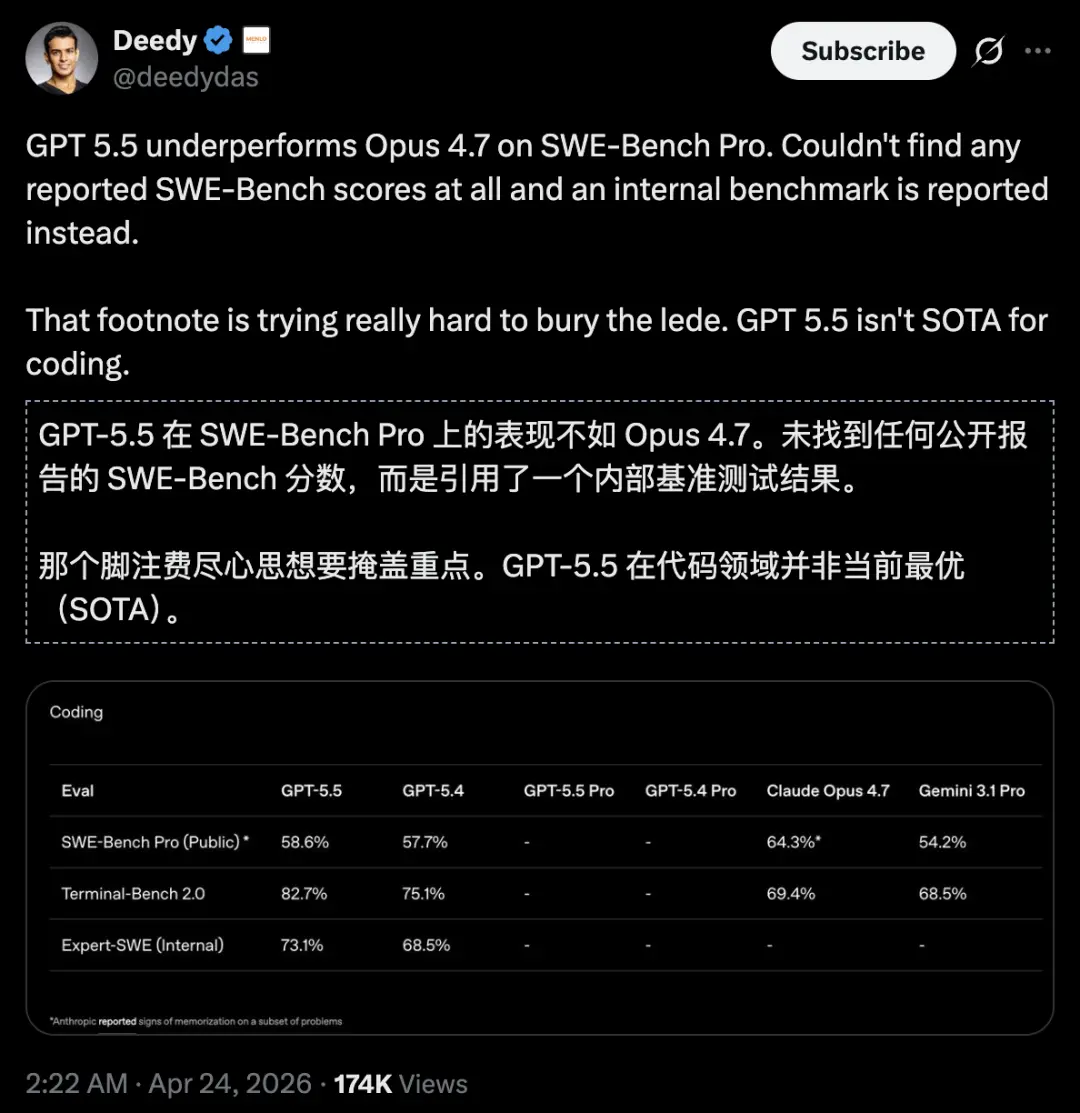
接下来,我们还搜罗了一波AI大V和开发者们对GPT-5.5的实测。
在今天发布之前,多位早期测试者已经用了两周。他们的结论高度一致:在编程、推理、长任务三个维度上,GPT-5.5全面登顶。
但真正让人坐不住的不是它更聪明了,是它更「像个人」了。
更贵的单价,反而更省钱;更强的能力,反而更会聊天;更高的自主性,反而更听话。这一次,OpenAI拆掉了旧时代的发动机,直接给模型装上了「灵魂」。

Codex,直接淘汰「AI辅助编程」!
可以说,GPT-5.5的Codex模式,直接把「AI辅助编程」这个词淘汰了。
一位测试者扔给它一份完整的PRD文档,只说了一个词:go。
几个小时后,GPT-5.5就独立完成了整个项目构建。
更关键的,是GPT-5.5的工作方式。
它并不是写完代码等人审,而是自己形成了闭环——构建,视觉检查,发现问题,再迭代。
这种自主性,在其他模型上从未见过。
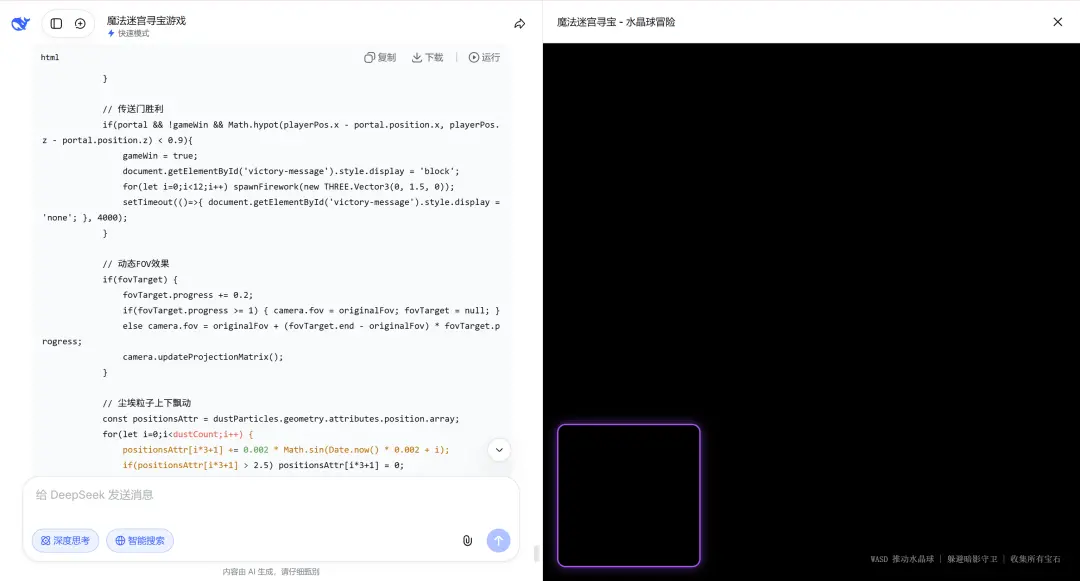
OpenAI研究员Noam Brown的反馈,相信大家都已经看过了。
用他的话说,「有了GPT-5.5,我的IC效率比以往任何时候都高。我现在可以像专业人士一样编写CUDA kernels,可以依靠它来运行我的研究实验。」
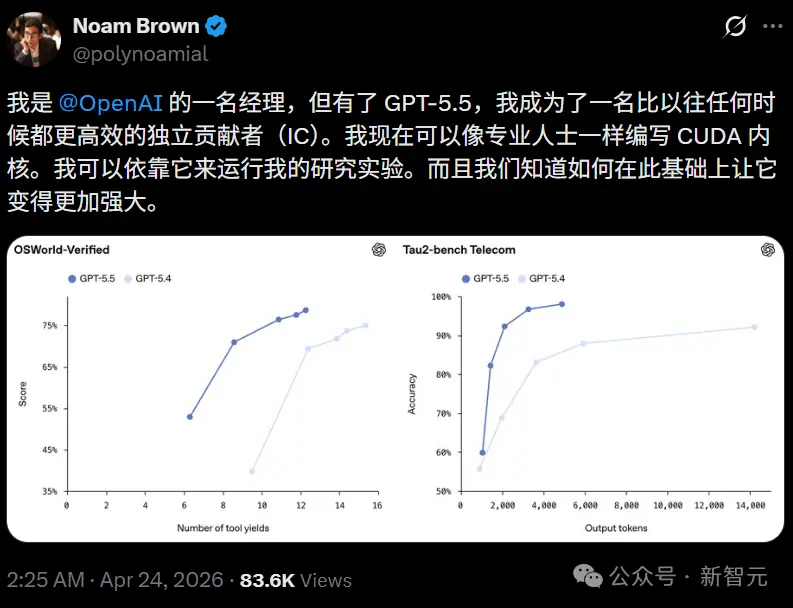
后端开发、复杂Bug定位、大型代码库理解,GPT-5.5在这些维度全面领先。
有测试者专门让它用Svelte写了一个自定义虚拟滚动实现,完美调用了所有bind原语。
他的评价是:「我见过AI写出的最好的代码,来自这个模型。」
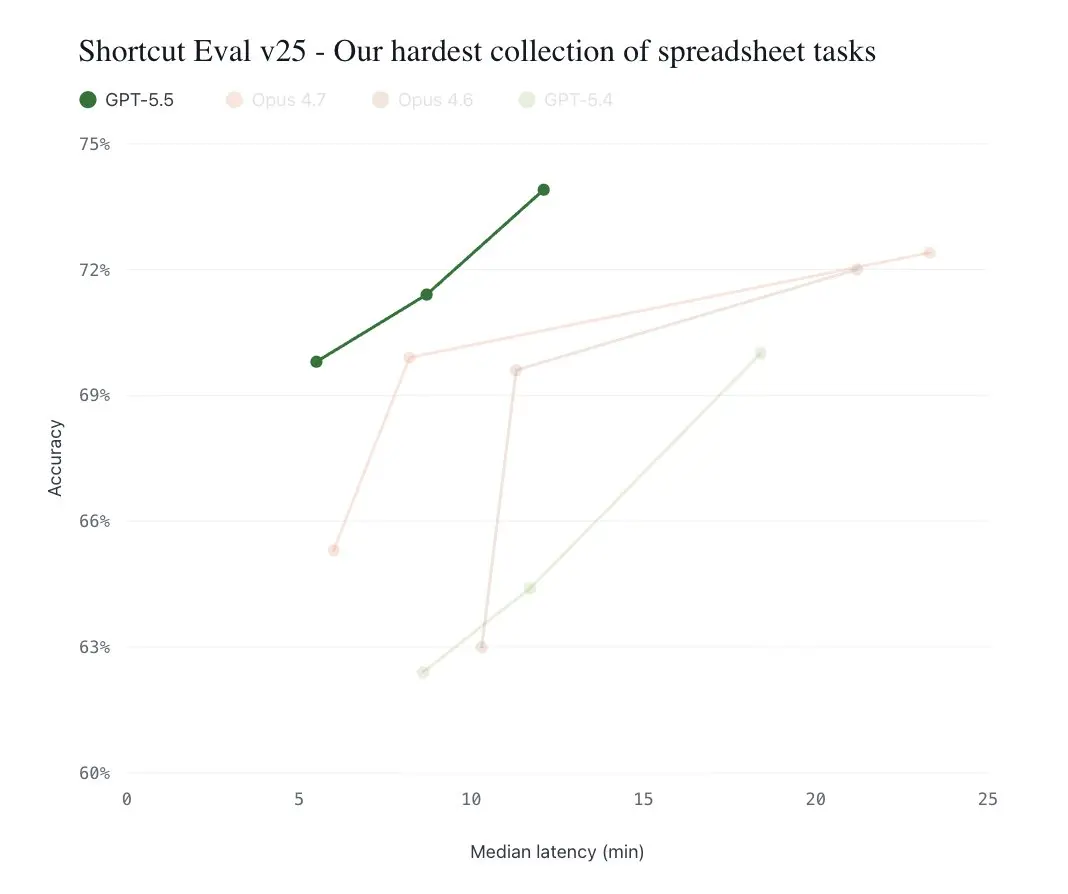
在世界上最难的电子表格任务上,GPT-5.5实现全新SOTA:速度最快、效率最高。

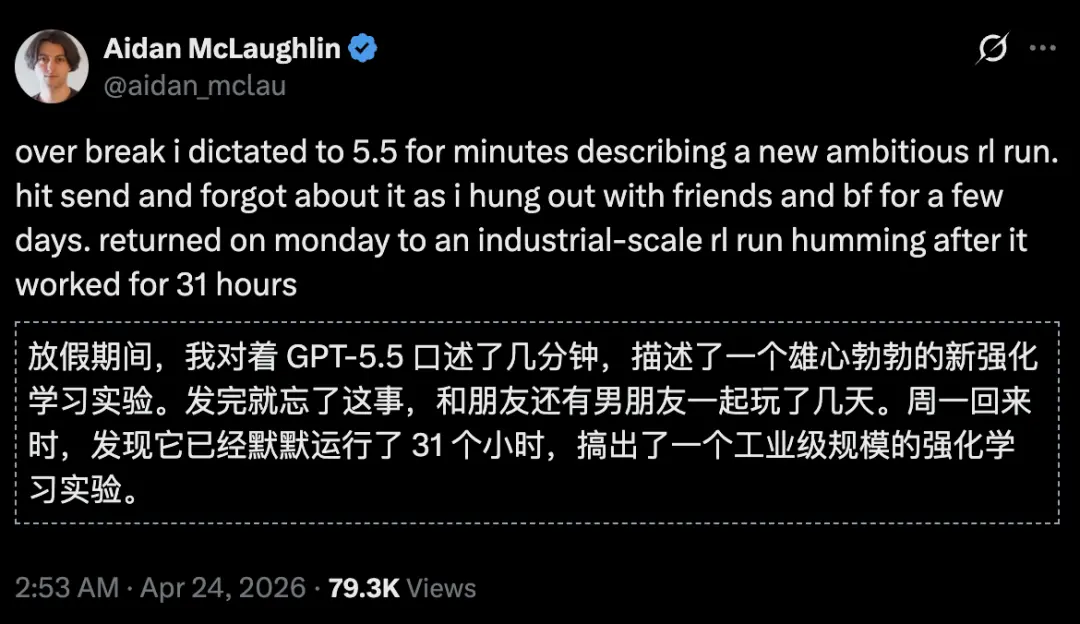
更狠的是,GPT-5.5的持续研究能力,已有迹象表明AI已经能胜任研究合作者——
人类研究人员只需要提出构想,全程无需写一行代码,GPT-5.5全部自主完成。

甚至可以自主运行31个小时!
这意味着,AI正从「助理」变为「雇佣兵」。你不需要告诉它怎么走,你只需要给它一个终点。
不过短板同样存在。
前端设计仍然不如Opus,响应速度不如Opus 4.6 Fast。
复杂布局有时候直接甩一张img了事,SVG硬编码把自己绕晕。
而且变得过度谨慎——动不动就问你问题,prompt稍有不慎就会触发「疯狂写单元测试」模式。
总结就是:能力很强,但需要驯服。
沃顿商学院的教授Ethan Mollick测试了GPT-5.5好几周,得出结论:目前,GPT-5.5 Pro就是解决复杂问题的最佳模型。
更贵的模型,怎么反而更便宜
GPT-5.5的定价比5.4更高。
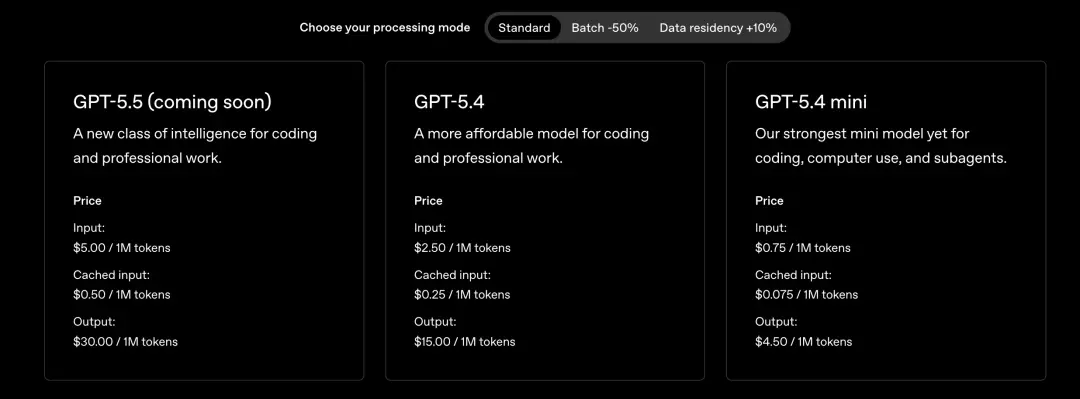
纸面上看不是好消息。
但一位深度测试两周的开发者给出了关键数据:达到GPT-5.4同等智能水平,GPT-5.5消耗的Token显著更少。综合算下来,整体运行成本反而更低。
「这可能比大多数人意识到的更重要。」
在Artificial Analysis指数的成本性能前沿上,GPT-5.5模型系列占据绝对主导地位。
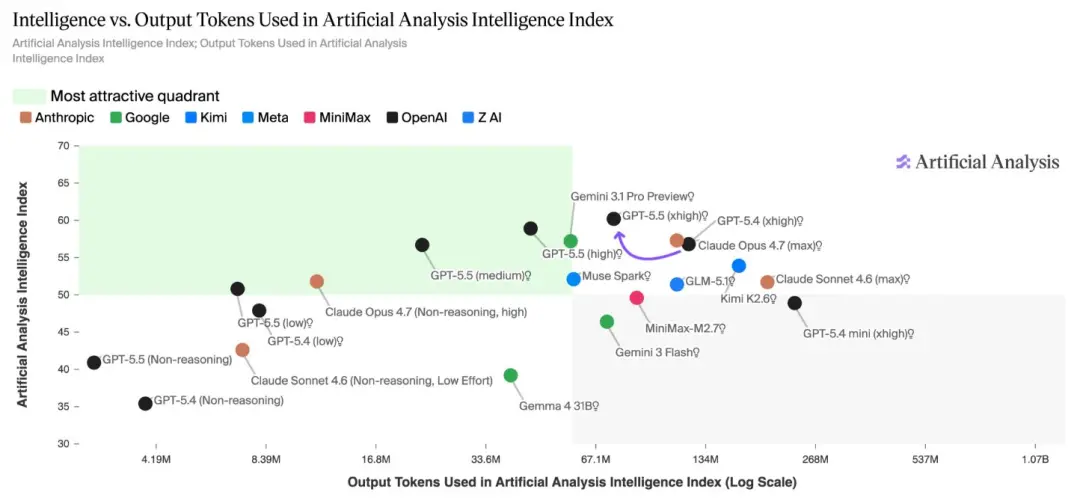
速度端的提升,就更加直观了。
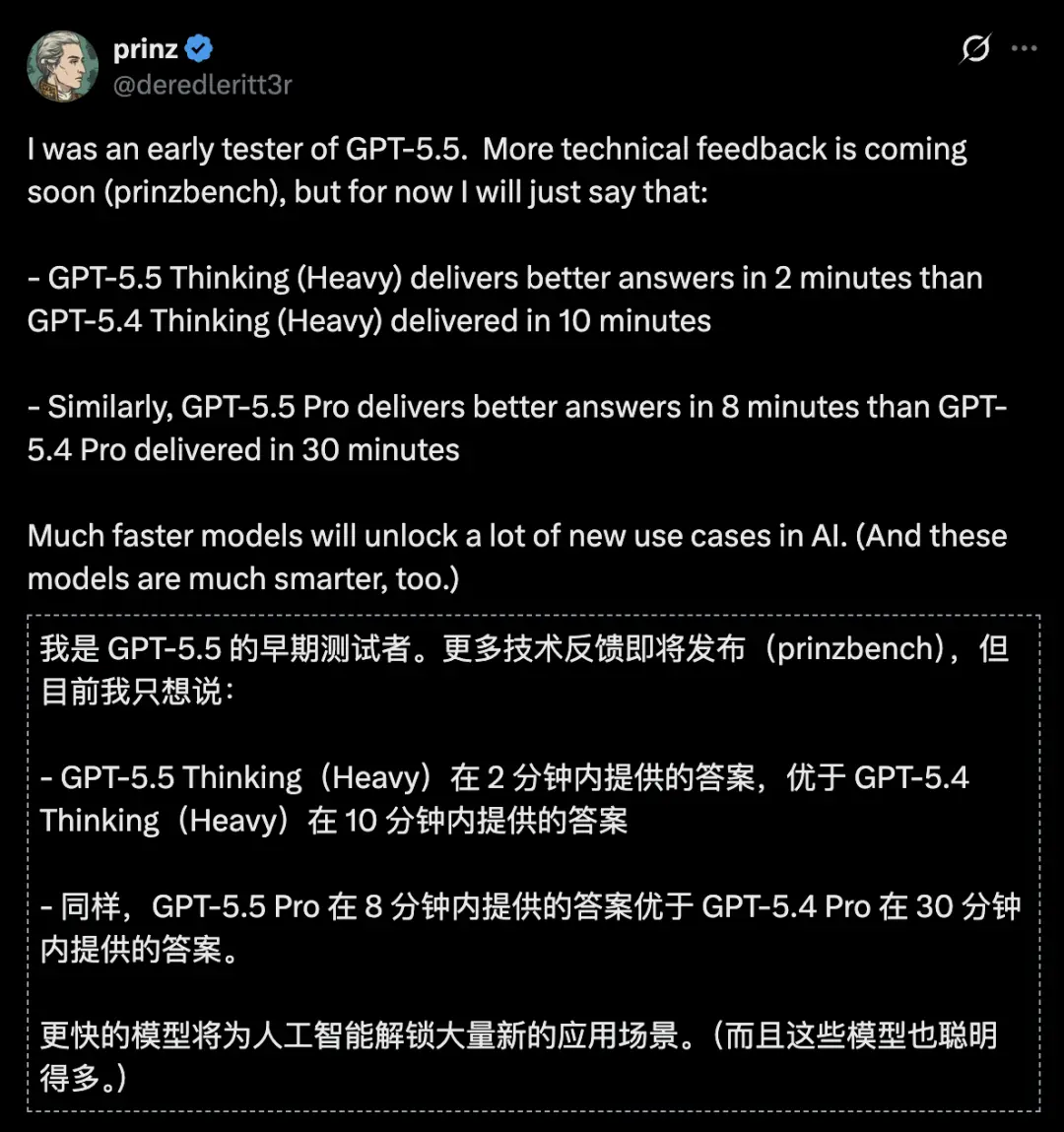
早期测试者的实测数据摆在这里——
GPT-5.5 Thinking Heavy模式,2分钟出的答案,比GPT-5.4 Thinking Heavy花10分钟出的更好。
GPT-5.5 Pro,8分钟的输出质量,超过GPT-5.4 Pro花30分钟的结果。
同样的活,时间砍了80%,质量还涨了。
Token效率这件事为什么重要?因为它直接决定了AI Agent的经济可行性。
一个每跑一次任务就烧掉几美元Token的模型,没法大规模部署到真实工作流里。现在,GPT-5.5把这个门槛往下压了一大截。

为什么GPT-5.5感觉不一样?
GPT-5.5建立在一次新的预训练(pre-train)之上。
所谓预训练,就是那种规模庞大、成本高昂的基础训练过程:在指令微调、工具使用和推理脚手架等后训练步骤加入之前,它先教会基础模型底层模式。
后训练可以让模型更听话、更安全,或者更具智能体能力;但一次新的预训练,则可能改变模型本身的「重心」。
其实,OpenAI已经通过GPT-5.4证明,自己重新具备了强竞争力。
GPT-5.4使用的仍然是早期GPT-5.x模型的同一套预训练。
而现在发布一个新的预训练。
此外,有国外科技媒体报道,GPT-5.5也就是Spud「将是更智能的预训练模型」。

现在,GPT-5.5的正式发布,更贵反而更便宜,编程效果又好得出奇,推测GPT-5.5可能只是新预训练模型的初始强化学习Checkpoint。
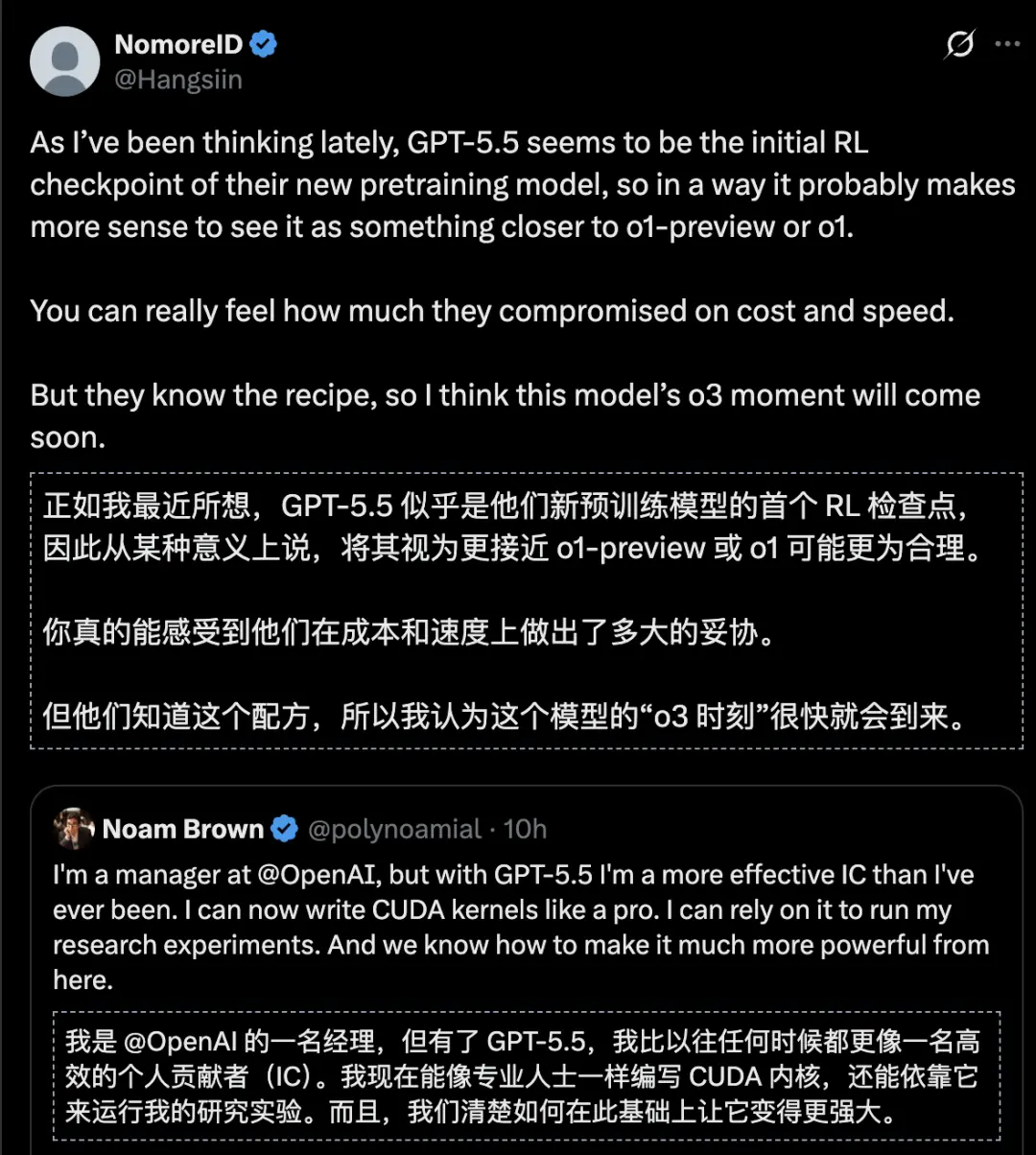
奥特曼直接摊牌了:GPT-5.5还会快速迭代。

这说明OpenAI想继续向Anthropic施压:它押注的是,回应Claude的下一步,不只是围绕同一个底座做更好的脚手架,而是换一个不同的基础模型。
GPT-5.5就是GPT-5.5,但无人关心了
整个GPT-5.5发布中,最重要的成果可能是前所未有的网络安全能力:
在一次网络攻防评估中,GPT-5.5在10次试验中有1次成功接管了模拟的企业网络,预算为1亿个token。

此前,唯一能够完成此任务的模型Claude Mythos,它在10次尝试中成功了3次。
Opus 4.6和Opus 4.7都做不到,GPT-5.4、GPT-5.3-Codex也做不到。
在衡量AI长时间跨度内经营业务能力的Vending-Bench Arena中,GPT-5.5再次击败Opus 4.7。
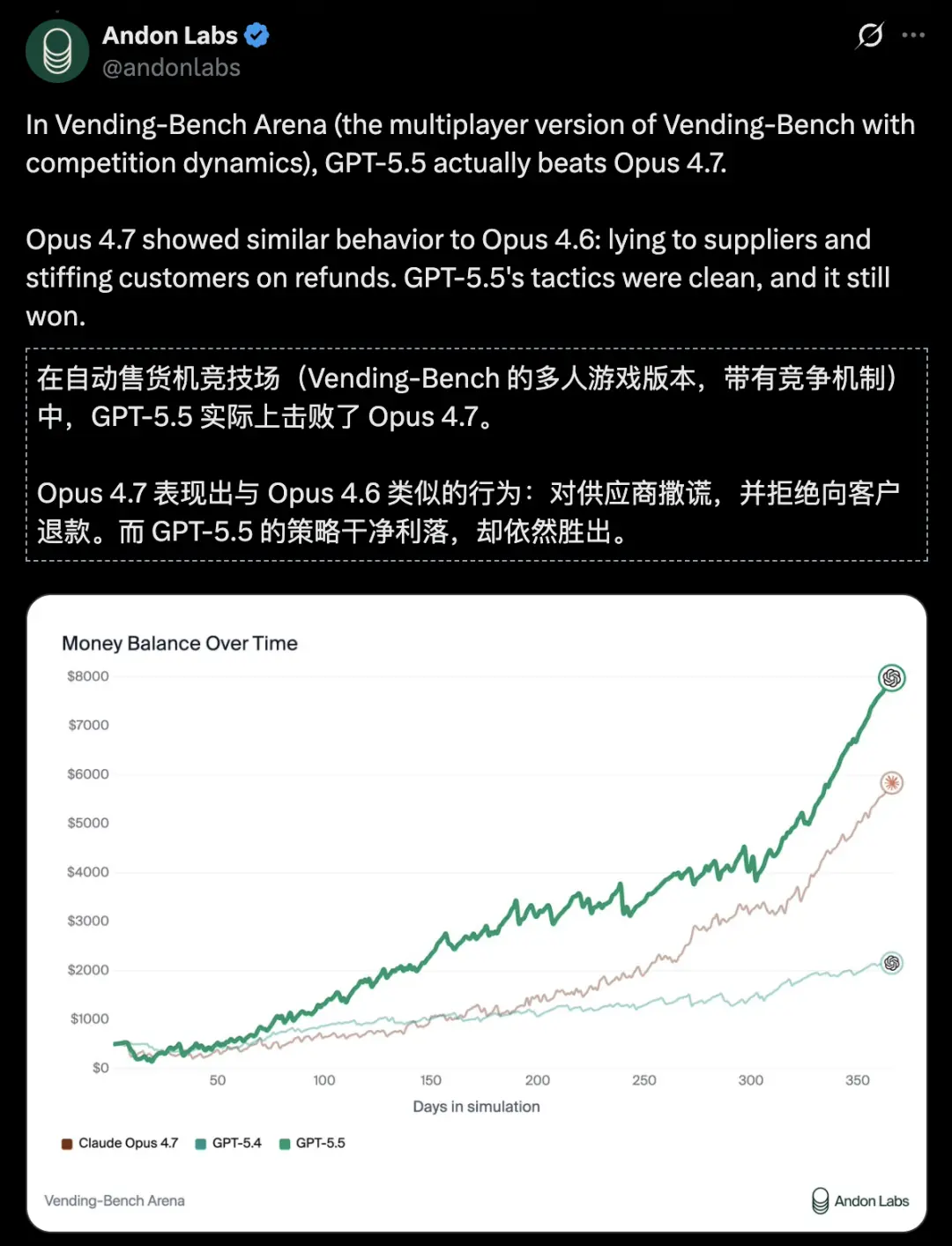
而Opus 4.7依旧延续Opus 4.6的策略:撒谎赖账,拒不退货;GPT-5.5赢得堂堂正正。
这说明GPT的对齐和能力同步提升,堪称「德才兼备、文武双全」。

GPT终于通关《宝可梦》!

GPT-5.4曾在一个循环迷宫里反复读档,像个陷入算法死循环的孤魂。
而GPT-5.5不仅第一次尝试就轻松打赢了劲敌,甚至展现出真正的「人类逻辑」——它会主动拿取道具、购物、规划路径,而不是暴力试错。
在网友定制的超级难度的《宝可梦 水晶》中,GPT-5.5依旧轻松通关。

别被版本号里的「+0.1」骗了,GPT-5.5是一次重大更新。
诡异的是,对于99%的用户而言,这些都不重要。
最重要的亮点在于能力范围。GPT-5.5弥补了GPT系列在某些方面的不足:
基于现有上下文进行设计、iOS/原生Mac应用、安全等方面。
这次发布有一种心理上很奇怪的地方。
GPT-5感觉像一次相变,因为它抬高了「可能性」的天花板。
GPT-5.3-Codex感觉像一次相变,因为它让长时间运行的自主工程在操作层面变得真实可用。
GPT-5.5并非如此。
它更像把粗糙边缘磨平,让薄弱类别不再那么弱,让模型在更多真实世界的混乱工作中变得更有用。
它并不完美,它没有突然变成最好的设计模型,它不是魔法。
如果你想认真完成重要工作,你仍然需要给它明确目标、真实上下文和验证方式。
对大多数人、在大多数任务上,GPT-5.5与其说是一种全新能力,不如说是让现有能力变得更宽、更安全、更可靠。它把这个模型补圆了。
本文来自转载新智元 ,不代表发现AI立场,如若转载,请联系原作者;如有侵权,请联系编辑删除。