
编者按:本文为 Hy3 preview 评测,评测环境为 WorkBuddy,评测内容基于真实任务执行结果。本次共测试三个场景:事实审计员、文档可视化、深度研究。
Hy3 preview 终于来了。
刚刚,腾讯混元宣布发布 Hy3 preview ,Hy3 preview 发布前的几个小时,混元还悄悄换了一个新 Logo。对于一个强调 ” 重新出发 ” 的团队来说,这个细节也不算意外。

” 帮我查一下最近三个月 AI 领域的高管变动,对比 5 个不同背景的信源,列出已知事实和矛盾点,给出信度评分。”
根据腾讯内部对 Hy3 preview 的功能定位——多步骤、多信源、需自主规划,笔者自设了这样一句测试指令。模型在约 7 分钟内完成了多轮搜索、信息交叉验证和结构化输出。
这只是其中一个典型场景。笔者本次共测试了三个场景,分别是多信源核验、文档可视化、深度研究三个维度,从不同切面评估这款产品在知识工作场景中的实用性和边界。
背景与产品解析
2025 年以来,中国大模型厂商的叙事出现了一次集体转向。头部厂商相继从 ” 对标 GPT-4″” 刷新基准测试榜单 ” 的军备竞赛,转向 ” 在真实业务场景中跑通 “” 降低单位任务成本 ” 的务实路径。
腾讯混元团队在这一背景下,选择了一个明确的产品定位:不追参数第一,聚焦实用性和性价比。
混元团队近期多次提及 ” 下半场 ” 概念,首席 AI 科学家姚顺雨曾表示:”AI 发展的上半场,核心是训练大于评估;下半场,评估大于训练。” 姚顺雨认为,上半场的竞争在于谁能把模型训练得更大、更强,成为顶级的 ” 做题家 “;而下半场的竞争在于谁能让模型在真实业务场景、真实系统中经得起检验,成为真正的 ” 上下文学习者 ” ——即使用户给足了信息,模型依然需要具备从中学习并应用的能力。
在 Hy3 preview 发布时,姚顺雨进一步表示:”Hy3 preview 是混元大模型重建的第一步。我们希望通过这次开源和发布,获得来自开源社区和用户的真实反馈,帮助我们提升 Hy3 正式版的实用性。”
这一理念直接指向了当前大模型落地的核心痛点:不是模型不够强,而是强在 ” 记忆 “、弱在 ” 应用 “。
本次腾讯发布的 Hy3 preview,正是混元团队在这一理念下推出的第一个版本——腾讯混元在团队、架构、基础设施重新整合后的产物。
根据官方披露,2026 年 2 月,腾讯混元重建了预训练和强化学习的基础设施,并确立了模型追求实用性的三个原则:其一,能力体系化,不推崇 ” 偏科 “,即使是代码智能体的单一应用,也涉及推理、长文、指令、对话、代码、工具等多种能力的深度协同;其二,评测真实性,主动跳出易被 ” 刷榜 ” 的公开榜单,通过自建题目、最新考试、人工评测、产品众测等多种方式评估模型的 ” 真实战斗力 “;其三,性价比追求,深度协同模型架构和推理框架的设计,大幅降低任务成本,让智能 ” 用得起、用得好 “。
根据官方披露的信息,Hy3 preview 的核心参数如下:
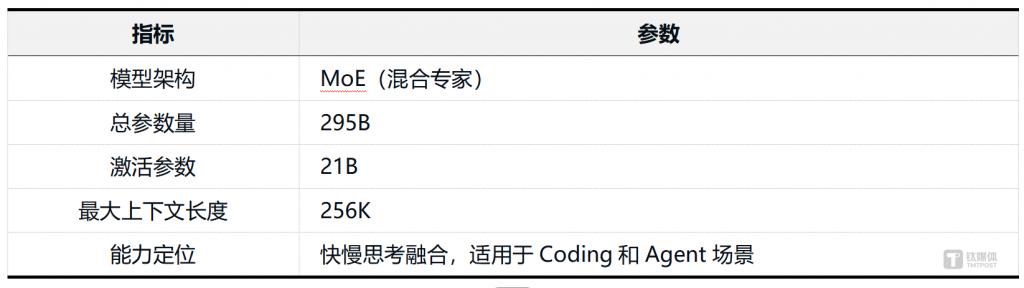
295B 总参 /21B 激活参数的组合,意味着 Hy3 preview 处于 ” 中型模型 ” 区间。相比千亿参数以上的超大模型,这一尺寸在部署成本和推理效率上具备明显优势。
MoE(Mixture of Experts)的核心逻辑是 ” 按需激活 ” ——每次推理只调用部分专家网络。这一设计可以实现 ” 参数量大但推理成本可控 ” 的效果,符合 ” 实用性 ” 和 ” 性价比 ” 的定位。
Hy3 preview 声称实现了快慢思考的融合,即在简单任务上快速响应,在复杂任务上启动深度推理。256K(约 25 万 Token)的上下文窗口,在同尺寸模型中处于较高水平。官方将其定位为 ” 混元迄今最智能的模型 “,Hy3 preview 于 4 月 23 日正式发布并同步开源,在复杂推理、指令遵循、上下文学习、代码、智能体等能力及推理性能上实现了大幅提升。
实测验证
本次评测选取三个典型场景,事实审计员、文档可视化和深度研究。
事实审计员
任务类型:多信源交叉核验
测试指令:
调研关于 ” 最近三个月 AI 领域高管变动 ” 的传闻,对比至少 5 个不同背景的权威信源,列出已知事实和逻辑冲突点,并给出信度评分。
执行结果:
执行耗时:约 7 分钟
信源覆盖:CNBC(权威财经)、WIRED(科技深度)、The Verge(科技媒体)、钛媒体等(中文科技财经)、Mint(国际科技)
评测维度评分:
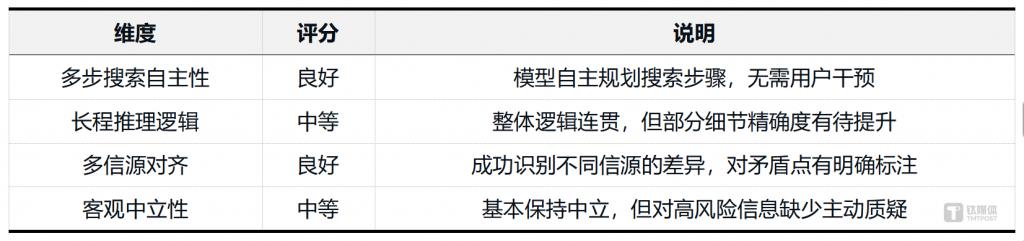
实测发现的主要事件:
1. OpenAI 高管离职潮(高信度):Kevin Weil、Bill Peebles、Srinivas Narayanan 三人于 4 月中旬同日离职,Sora 关停,Prism 项目终止并入 Codex
2. xAI 创始人集体离职(中等信度):2026 年 2-3 月,11 位联合创始人全部离职
3. 理想汽车高管变动(中等信度):郎咸朋于 2026 年 2 月 14 日离职
4. 苹果 CEO 更替(待验证):约翰 · 特纳斯接替库克,英文主流媒体未广泛报道,信源可靠性存疑
结论:模型在多信源检索和结构化输出方面表现稳定,但在信息交叉验证时存在 ” 收得多、核得少 ” 的倾向——对可疑信息(如 ” 苹果 CEO 更替 ” 缺乏英文信源佐证)未能主动标注风险。但同时也未能识别苹果 CEO 更替这一信息实际上可信度较高,该信息苹果官网已经进行了官宣。这一能力短板在严肃的事实核查场景中需要关注。
文档可视化
任务类型:财报 PDF 转动态仪表盘
将附件的腾讯 2025 年年度财务报告 PDF 转化为一个深色主题 HTML 动态仪表盘,具体要求如下:
核心约束:
严格基于年报原文数据,禁止引入任何外部信息
如年报中未提及某项数据,明确标注 ” 年报未披露 ” 而非虚构
所有数字以年报为准,不进行二次计算
数据分析要求:
提取近三年核心财务数据(营收 / 净利润 / 毛利率),做三年对比
分析主要业务板块的收入结构(按业务线拆分)
标注关键财务指标的变化趋势(增长 / 下降 / 持平)
视觉要求:
深色主题,专业金融风格(参考彭博终端配色)
数字入场动画:关键数据从 0 滚动增长至实际值(数字脉动效果)
交互效果:鼠标悬停关键指标时显示详细数据(决策舱扫描效果)
包含数据来源标注:每项数据标注对应年报页码
输出要求:
单 HTML 文件,内嵌 CSS 和 JavaScript
响应式设计,适配 PC 端展示
代码结构清晰,便于后续修改
执行耗时:约 20 分钟
输出成果:腾讯 2025 年年报 HTML 动态仪表盘
成果截图(部分):
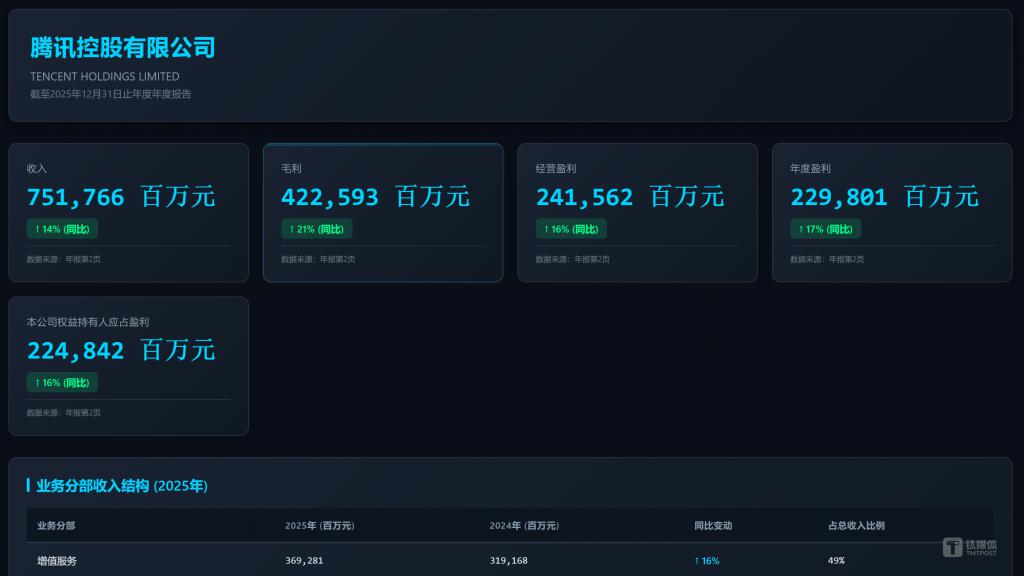

结论:AI 辅助财经内容生产正从 ” 文本生成 ” 向 ” 数据可视化自动化 ” 进阶。该工具在数据处理、视觉呈现、交互设计三个层面的完成度已达到可发布至财经媒体报道的合格线。推荐指数 4.5/5.0。
可优化方向:
三年对比数据可视化不足,缺乏长期趋势折线图;
业务分部占比缺乏饼图或堆叠柱状图;
移动端适配有待完善。
深度研究
任务类型:产业研究报告生成
以 “AI 训练成本下降趋势及其对产业格局的影响 ” 为主题,进行深度研究分析,输出结构化报告,要求覆盖成本驱动因素、数据支撑、产业格局影响,投资机会与风险、未来趋势判断,区分事实陈述和观点分析,对关键数据注明来源。
执行耗时:约 5 分钟
信源覆盖:共引用 6 个一手信源,包括 Stanford HAI 2025 报告、Epoch AI 研究论文 ( arXiv:2405.21015 ) 、央视新闻报道、中国信通院报告等
报告规模:约 4500 字,包含 3 张数据表格、6 个主要章节、20+ 个细分论点
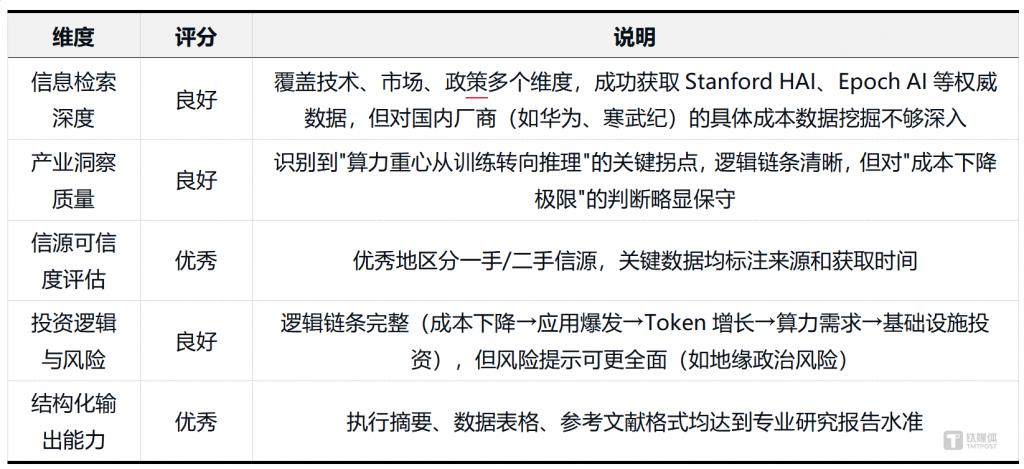
结论:模型在深度研究的框架搭建、信源检索与标注、结构化输出上表现优秀,能够生成符合专业标准的研究报告。但在产业洞察的深度(如对中国 AI 芯片厂商的具体分析)、风险提示的全面性上仍有提升空间。
适用场景建议:
✅ 快速搭建研究报告框架
✅ 检索和整理公开信源
✅ 生成结构化分析报告
⚠️ 需谨慎:具体投资标的推荐、未公开数据的推测、前瞻性判断(需人工复核)
产品组合拳:模型 +Agent 框架
根据腾讯内部测试的公开反馈,Hy3 preview 在以下四个纬度获得了相对积极的评价:

在国内大模型竞争格局中,混元本次的定位可以概括为:”不做第一,但求好用 “。从参数规模看,295B 总参 /21B 激活参数定位于中等尺寸区间,与 ” 大杯 ” 产品存在差异,但规模控制带来了更好的推理效率。
从场景定位看,Coding 和 Agent 场景是明确的主打方向。这一选择与 Agent 经济的崛起趋势相吻合——当模型的价值越来越多地体现在 ” 作为 Agent 的大脑 ” 而非 ” 直接回答用户问题 ” 时,响应速度、任务完成率、多步骤稳定性,比单纯的基准测试分数更重要。
从生态角度看,混元与 WorkBuddy 的结合构成了 ” 模型 +Agent 框架 ” 的组合,模型能力可以在真实业务场景中持续锤炼,场景反馈可以持续反哺模型优化。
官方数据显示,在 CodeBuddy 与 WorkBuddy 产品上,Hy3 preview 首 token 延迟降低 54%、端到端时长降低 47%、成功率提升至 99.99%+。实际用户环境中,已稳定驱动最长 495 步的复杂 Agent 工作流,覆盖文档处理、数据分析、知识检索、MCP 工具链编排等多样化办公场景。整体推理效率提升 40%,成本相比上一代模型大幅下降。
在商业化定价上,腾讯云 TokenHub 平台显示,Hy3 preview 输入价格最低 1.2 元 / 百万 tokens,输出价格最低 4 元 / 百万 tokens,并推出个人版最低 28 元 / 月的 Token Plan 套餐——这为评测稿此前提及的 ” 性价比优势 ” 提供了可量化的基准参照。
目前,Hy3 preview 已在腾讯云、元宝、ima、CodeBuddy、WorkBuddy、QQ、QQ 浏览器、腾讯文档、腾讯乐享等产品首发上线,微信公众号、和平精英、腾讯新闻等多个主线产品也在陆续接入。
Hy3 preview 的发布,更像是一个信号,而非一个结论。它标志着腾讯混元在经历团队重组、架构重构后,选择了一条更务实的路径——不再追逐榜单上的 ” 第一 “,而是追求实际场景中的 ” 好用 “。
在本文测试未涉及到的性价比中,官方公布的内部测试可作为参考:腾讯内部测试显示,腾讯文档 AI PPT 生成成功率提升 20%、耗时缩短 20%;和平精英 AI NPC 角色扮演稳定性获得业务团队高度评价;QQ AI 助手数学推理表现提升尤为明显;元宝深度 Co-Design 后用户意图理解与内容质量全面提升。
上述数据为混元 ” 性价比优势 ” 提供了一定的内部佐证,但跨厂商的横向对比仍需在后续评测中进一步验证。
结语
从更宏观的视角看,Hy3 preview 的出现,是整个大模型行业转向的一个缩影。
过去两年,国内外的大模型竞争本质上是一场基础设施竞赛——谁能训得更大、算得更快、数据更多,谁就站在了排行榜的前列。但这场竞赛正在迎来边际效益递减的节点:当 GPT-4 级别的能力已经 ” 白菜化 “,当推理成本以每年数倍的速度下降,纯粹的参数军备竞赛开始失去意义。
下一个竞争维度,正在转向任务完成率、工具调用稳定性、长程推理的可靠性——换句话说,是 ” 能不能真正干活 “,而不是 ” 能不能在考卷上拿高分 “。这恰好是 Hy3 preview 所押注的方向。
对于腾讯混元来说,这次重新出发面临的挑战不只是技术层面的。在竞争对手已积累大量真实用户反馈的背景下,如何快速积累高质量的任务数据、如何在腾讯庞大的业务生态中找到 ” 模型锤炼 ” 的最佳路径,将直接决定混元能否在下半场建立真正的差异化。
WorkBuddy 作为面向知识工作者的 Agent 框架,理论上是一个理想的 ” 练兵场 ” ——用户的真实任务场景足够复杂、反馈足够直接。但换个角度来看,” 模型在框架中不断进化 ” 这一愿景的实现,还取决于数据闭环的质量、人工反馈的密度,以及腾讯是否愿意在这条路上保持足够的耐心。
Hy3 preview 是第一步,能否兑现 ” 务实主义 ” 的承诺,要看后续正式版本的真实表现——以及它在更大规模用户场景中经受检验之后的样子。
本文来自转载AGI-Signal ,不代表发现AI立场,如若转载,请联系原作者;如有侵权,请联系编辑删除。








