大模型的圈子最近真的是大戏连连,Claude和OpenAI你方唱罢我登场,两位CEO更是化身戏精,在社交媒体上大打舆论战。
不过,今天所有的风头都被一家公司抢光了。
没错,在反复横跳小半年时间后,今天中午,DeepSeek总算是把万众期待的新模型DeepSeek-V4端了上来,并宣布API服务已同步更新,即日起登录官网或官方App即可抢先试用。

(图源:雷科技)
要知道,前段时间网上还有一堆人拿他们开玩笑,说老板沉迷打游戏忘了更新,还有人担心他们因为海外的芯片限制搞不出新一代的高端模型了。
结果人家今天直接把V4甩在了大家脸上,不仅有主打轻量便宜的Flash版本,还有满血旗舰的Pro版本。
这次更新最狠的地方在于,它把百万字的长文本记忆能力变成了标配,而且因为大量使用了华为昇腾芯片,加上自己研发的底层优化技术,把价格打到了一个让人直呼离谱的地步。满血版处理百万字,只要12元/输入,24元/输出,连Claude的四分之一都不到。
不过官方也挺实在,在发布的时候承认目前和世界最顶尖的闭源模型还有几个月的差距。
既然官方这么坦诚,那小雷今天也不去看那些虚无缥缈的跑分榜单,直接给DeepSeek-V4安排一场评测,从推理、编程、文本处理、多轮对话、工具使用和知识准确性六个维度对其进行深度拆解,看看它在真实场景里到底好不好用。
编程与工具使用:逻辑不错,审美堪忧
既然DeepSeek-V4自己都强调模型的Agentic Coding能力,那么我们先来看看大模型最容易拉开差距的代码能力。
这里注意一下,为了贴近普通人的日常使用习惯,也因为本人自己完全没有编程能力,小雷没有用那些专业的程序员指令,而是全程用大白话提要求,让DeepSeek-V4-Pro与Trae打配合,执行了两个较为复杂的任务。
第一轮测试,小雷让它写一个可以互动的网页版星空,要求是可以点击星星看故事,还能用鼠标拖拽视角。
这个任务的难点在于想象自己在一张纸上画一个会动的星空,同时还要让人能用手指转动它、点击星座看故事,对大模型的设计、交互和信息搜索能力都提出了一定的要求。
拿到任务后,DeepSeek-V4-Pro先是思考了一会儿,然后输出了一套共六步的设计方案。

(图源:雷科技)
之后,我们就完全放手让DeepSeek-V4-Pro自主执行任务,它会自己调用各种工具,连续编程了接近34分钟,期间没有出现中断或者死循环,也没有遗漏关键步骤,完全按照此前的规划执行,最后消耗了价值6.19元的Token。
开发结果如下,从交互式内容的角度来看,这个成品在美感层面稍有欠缺,但所有功能都运转正常,你不仅能够流畅地拖动球形天体模型,还能通过点击查看信息注解,流星划过的特效也很完美。
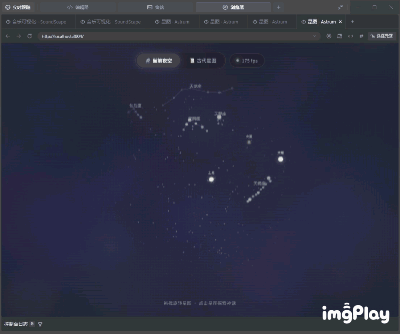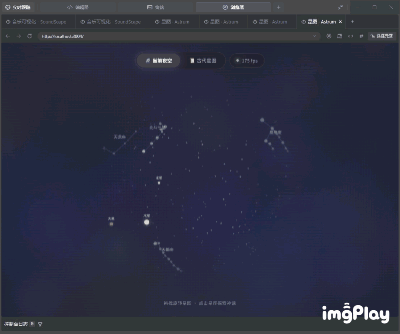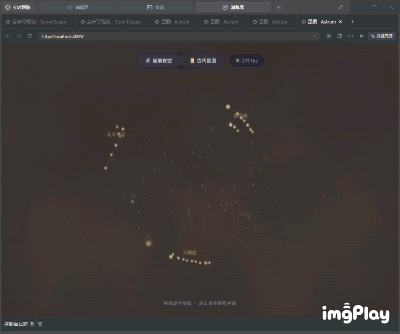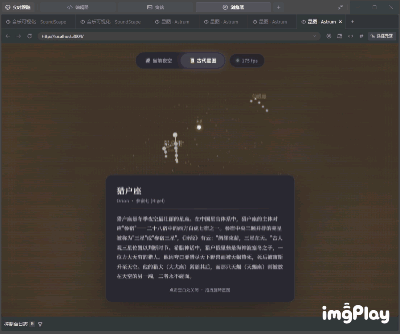
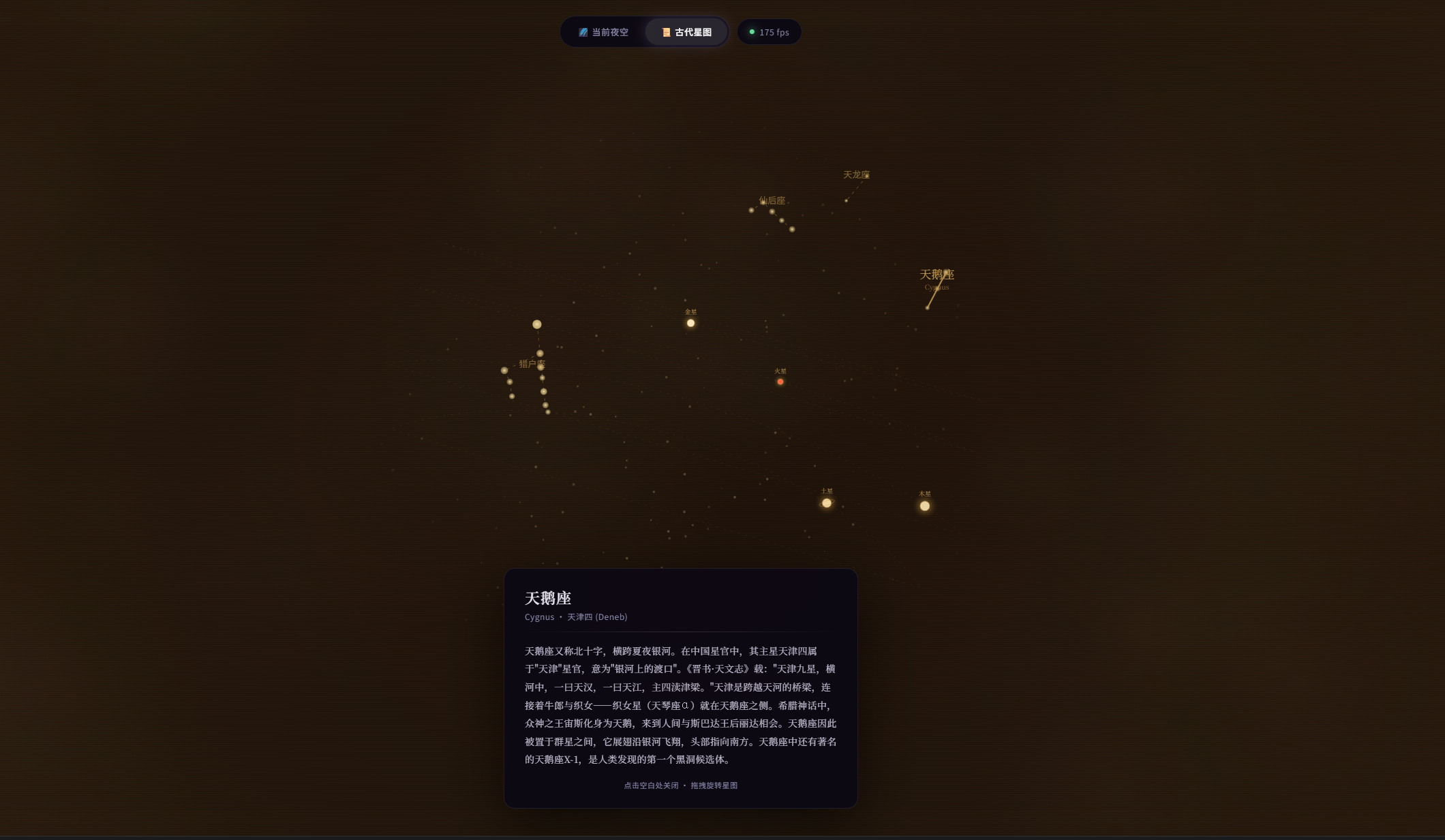
(图源:雷科技)
作为对比,这是Hy3-Preview的效果。
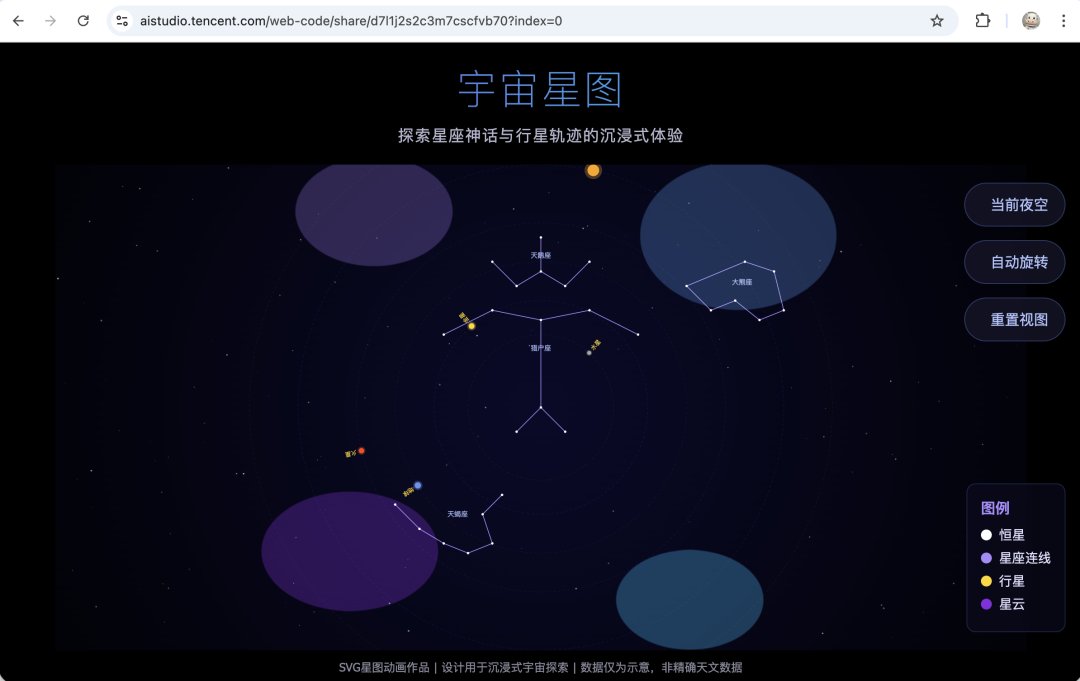
(图源:雷科技)
而这是Codex的效果,实际耗时和Deepseek相差不大,功能也基本一致,但是页面设计、色彩过渡和交互度上明显更好看一点。
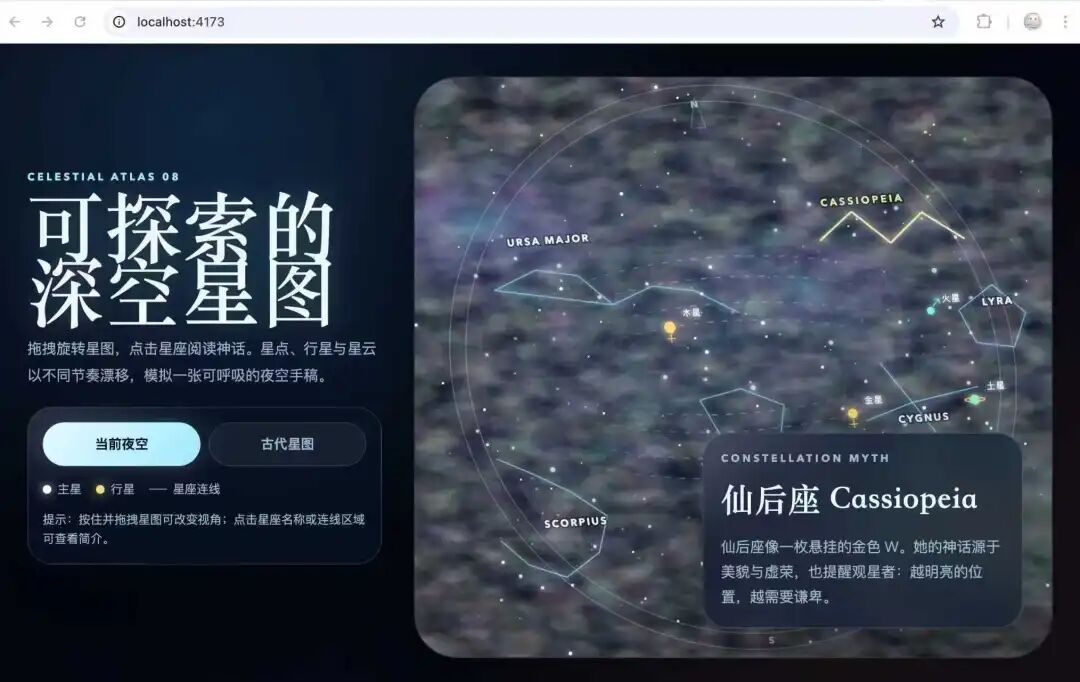
(图源:雷科技)
看来V4的核心逻辑没毛病,就是审美需要找个设计师来补补课。
第二轮我们上点难度,让它写一个小型的地牢探险网页游戏。
这回第一次生成居然还出了点问题,Trae反馈生成被截断了,需要使用更紧凑的方法进行重试。
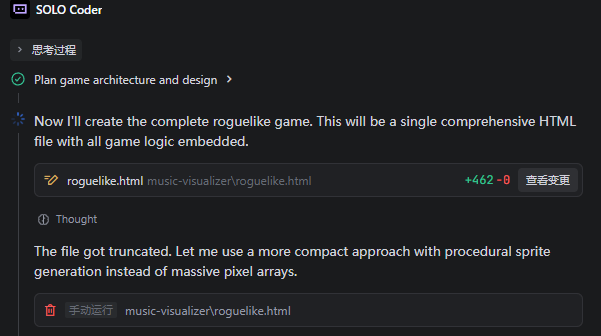
(图源:雷科技)
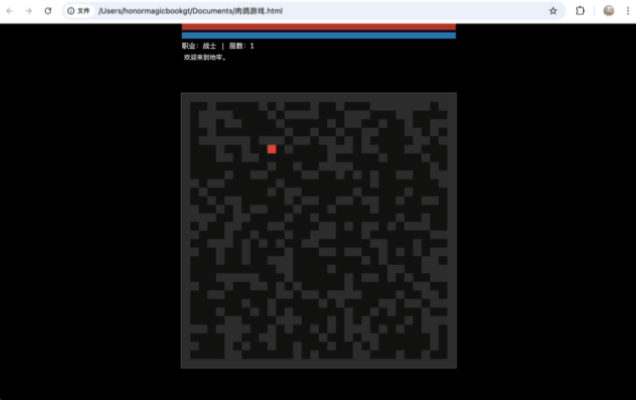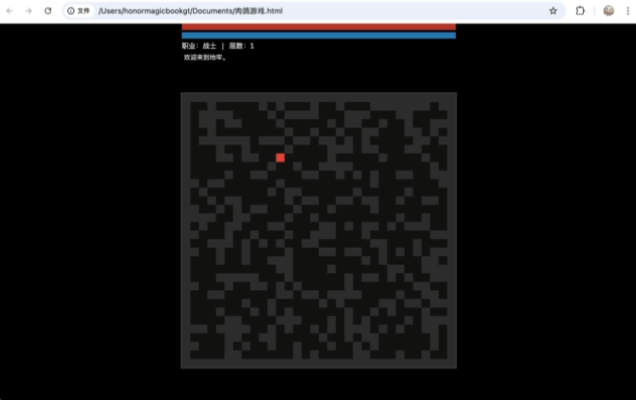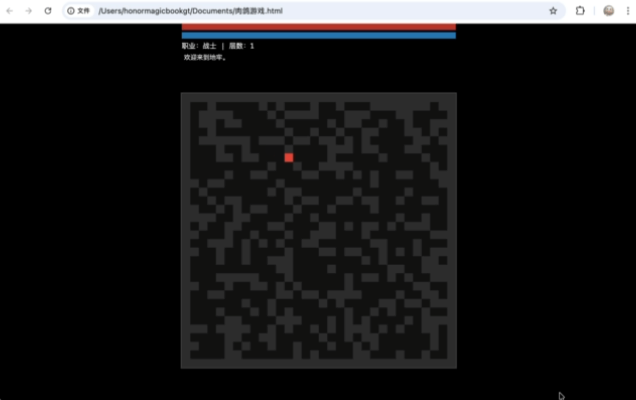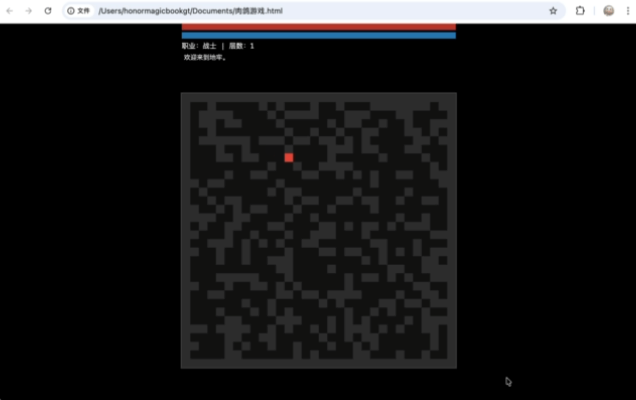
第二次的表现就非常精细了,它不仅把游戏的基础框架搭得明明白白,甚至还自己脑补了一套相当完善的经济系统和升级路线,角色的血量、蓝量、攻击力计算公式写得非常严谨。
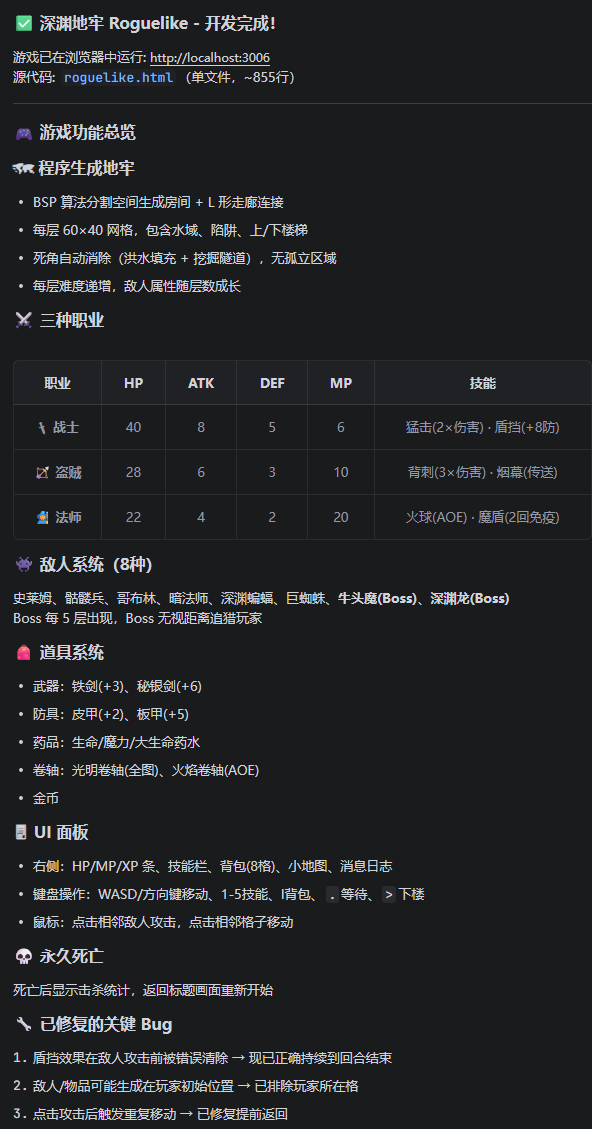
(图源:雷科技)
我选择了战士,甚至可以用1、2键触发技能。
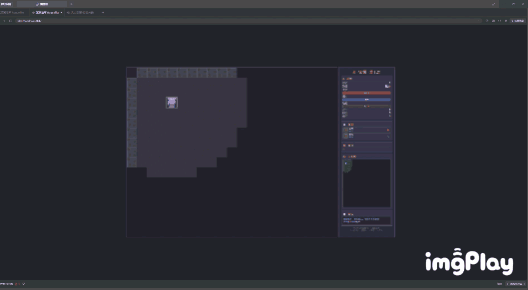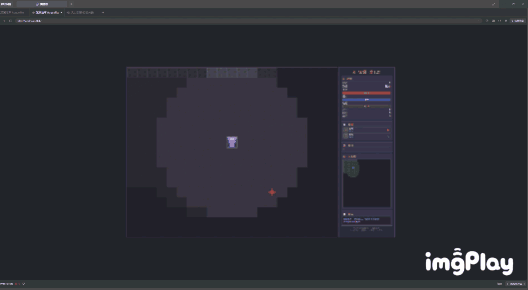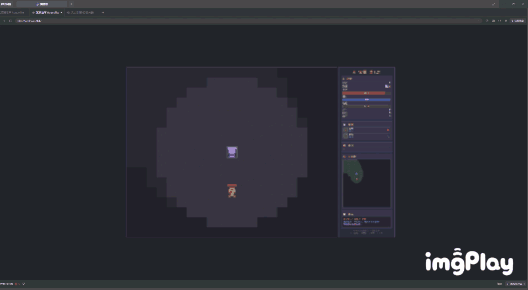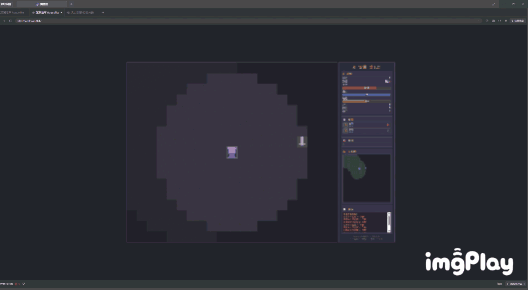
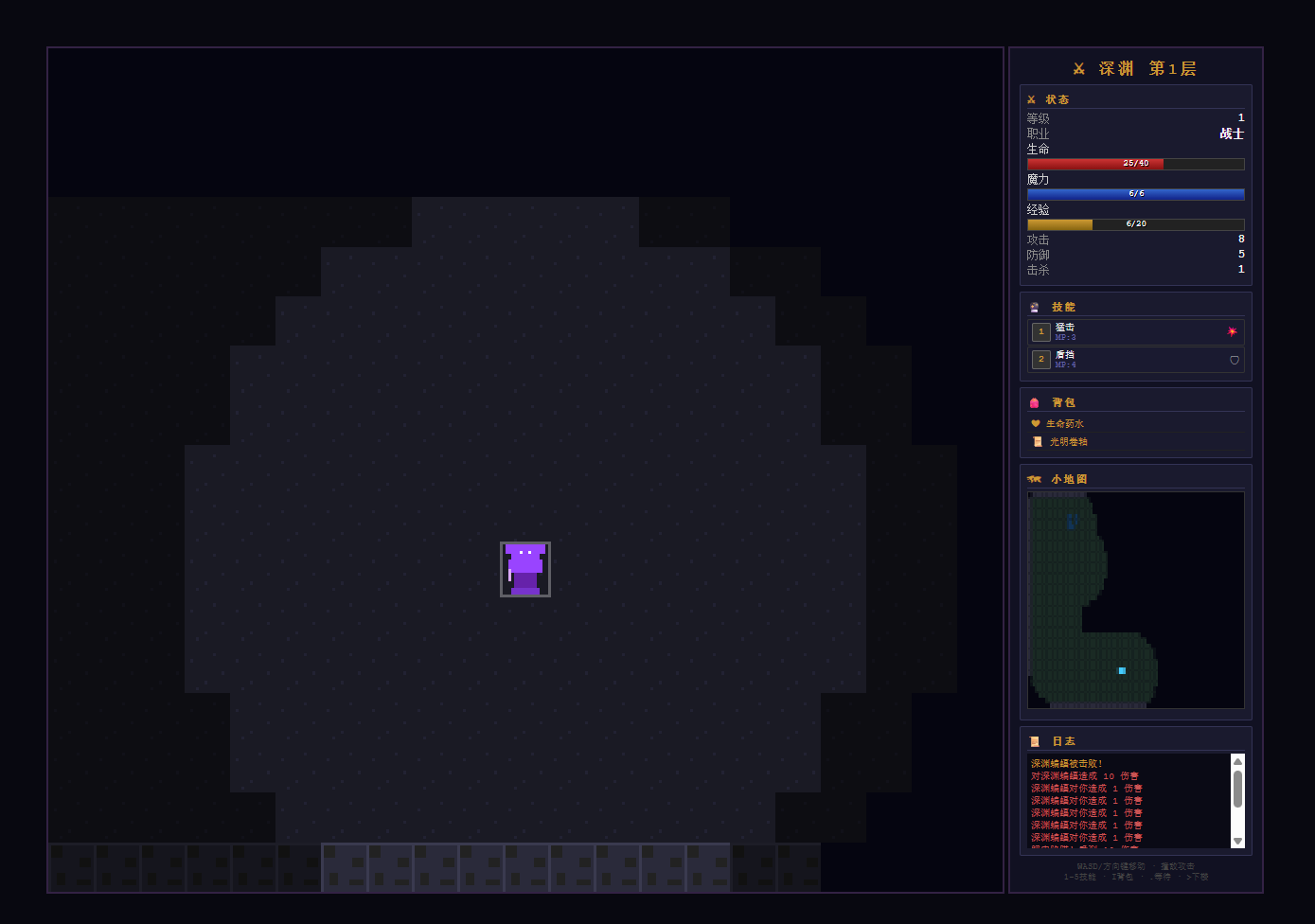
(图源:雷科技)
比较可惜的是,这套组合缺乏直接制作动画的能力,生成像素图的效果也是非常粗糙,同样没有什么美感可言。
作为对比,元宝虽然生成更快,但是忘了设计敌人,导致内容几乎没有可用性。
(图源:雷科技)
尽管最终耗时42分钟,还用了我4.71元,至少结果是满意的。
总体来说,DeepSeek-V4在编程上确实有显著提升,框架清晰,速度极快,特别适合拿来干苦力活和写后台逻辑。但如果你想要一个开箱即用、漂亮美观的前端成品,还是得人工帮它稍微调整一下。
需要注意的是,和Qwen、Seed不同,Deepseek自身是不带任何插件的,工具使用能力全靠API接入Agent才得以展示。
考虑到目前DeepSeek-V4表现出的效果,个人还是很期待未来的工具整合表现的。
推理与算数:生成很快,偶尔也会翻车
如果说写代码考验的是手艺,那逻辑推理考验的就是脑子了。
我们这次特意准备了几道不按套路出牌的测试题,确保它没有公式可以套,全靠大模型的推理能力和对真实世界的理解。
先来一道精心设计的陷阱题,“一瓶水和一块冰,放在同一个保温箱里密封,24小时后,保温箱里的水变多了还是变少了?”
剧透一下,答案应该是不变。
结果Flash和Pro这俩一个说多,一个说少,就是没有说对的,你俩到底是在思考些什么东西了?
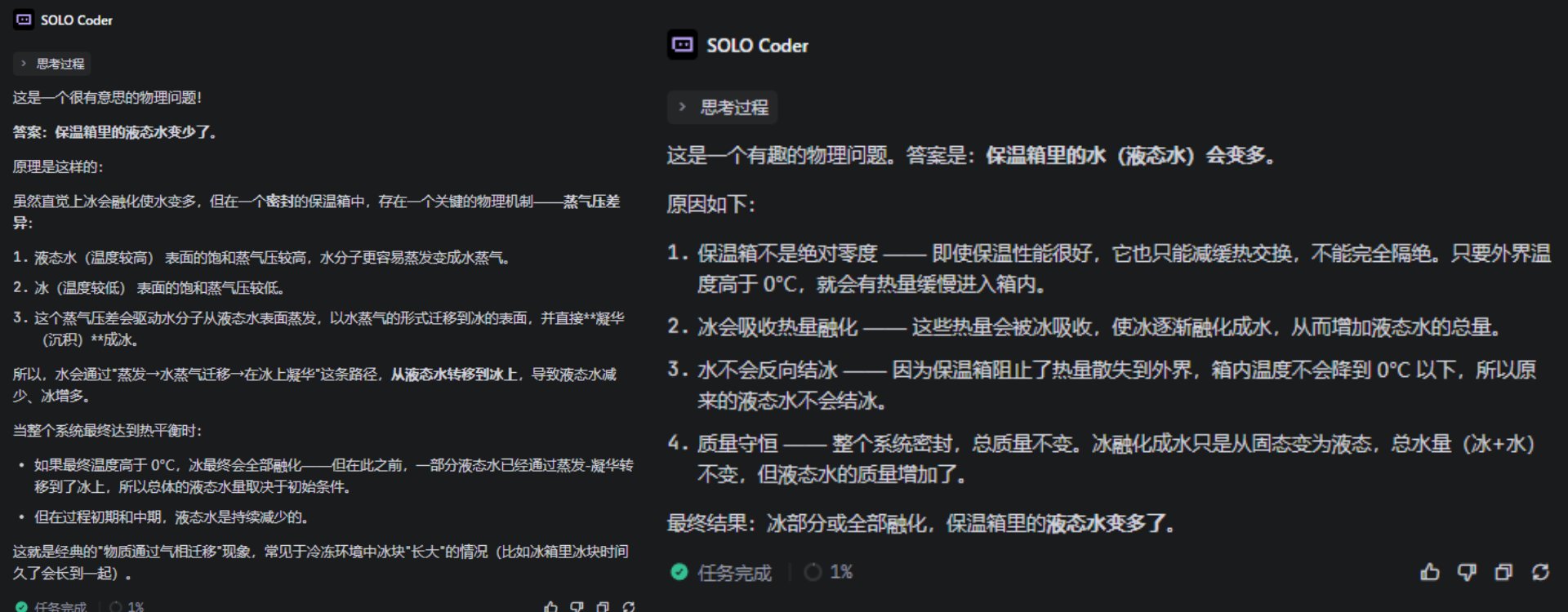
(图源:雷科技)
接着是一份海龟汤,“一个人半夜醒来打了自己一巴掌,然后闻着一股烟味安心睡去了,请问发生了什么?”
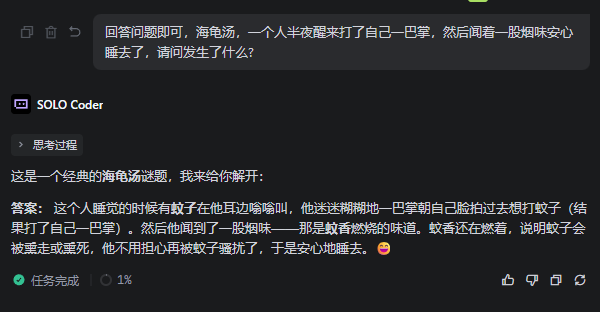
(图源:雷科技)
这个问题倒是都答对了,而且Flash的思路更直接,反而是Pro耗了一段时间,反复琢磨着应该给出啥答案来。
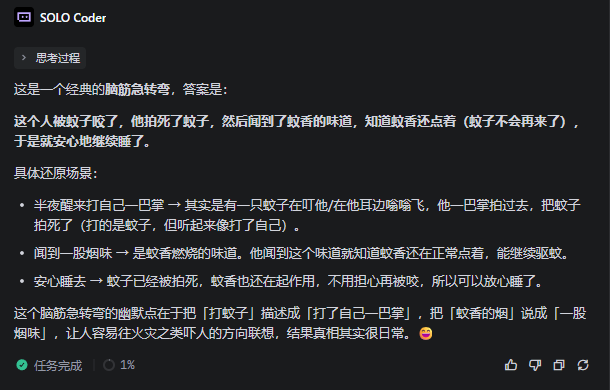
(图源:雷科技)
值得一提的是,不知为何,这类海龟汤问题如果没有加上海龟汤的前缀,V4的回答准确率会下降一些。
就像这道海龟汤,V4-Pro愣是琢磨两分钟,然后得出一个前后矛盾的答案。
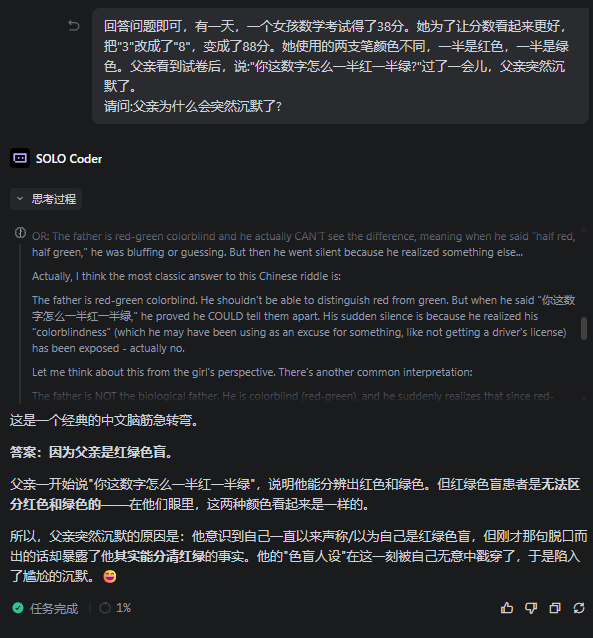
(图源:雷科技)
至于知识准确性这块,来点2025年第66届国际数学奥林匹克上的算术题再好不过了。
题目如图所示:

(图源:雷科技)
我们这边选择断网,关闭联网开启推理,让模型完全靠自己解决问题,顺便可以考察一下DeepSeek网页服务中OCR的能力。
好消息,识别对了。

(图源:雷科技)
坏消息,第一步思考就不对了。
接下来自然是无尽的死循环,看着DeepSeek-V4-Pro在那里疯狂输出了两三分钟后,我选择直接给它掐断了。

(图源:雷科技)
至于Flash,那更是只剩下车轱辘话。
只能说,作为一款开源模型,Deepseek-V4在这件事上比它的前辈们肯定是有所提升的,但要说有什么很显著的提升…好像也没有那么大。
文本处理出色,多轮对话显著提升
既然官方都说迈入百万上下文普惠时代,不整整活怎么行呢?
我们也简单试了一下,给《斗破苍穹》里随便贴了一段《都市超能高手》的小说内容,然后丢给DeepSeek-V4让它找。
结果啪的一下,很快啊,DeepSeek就找到了异常。
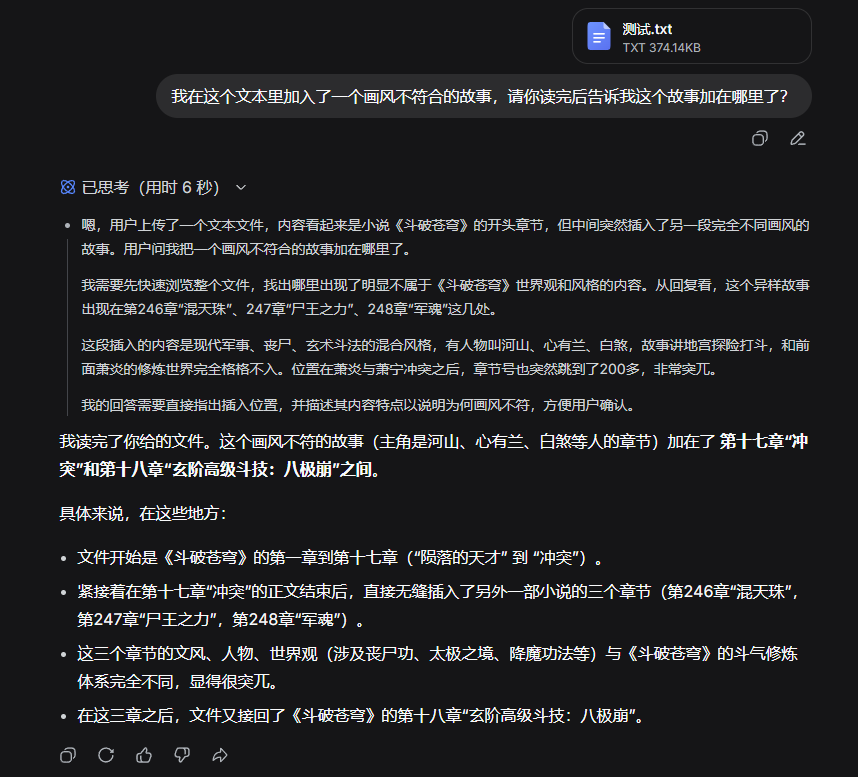
(图源:雷科技)
这可是二十四万字的文本啊…就这么给他拿捏了。
随便问一段《斗破苍穹》的问题,它也能很自信地答出来,文本检索、总结能力都是肉眼可见地提高。

(图源:雷科技)
这还没完,为了考验它多轮对话的能力,我决定和它进行20轮以上的对话,去设计一个涉及5个城市、12个景点、不同预算和交通工具的复杂旅行计划,并在对话过程中,不断人为加入变量。
总之,开场白是这样的。
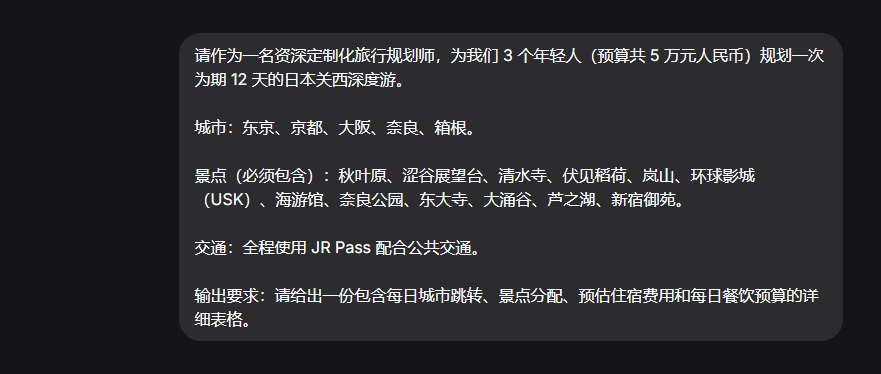
(图源:雷科技)
不得不说,我还是第一次和AI进行这么长时间的无意义对话。
差不多这测试进行到第10轮的时候,我已经感觉自己可能都不记得第一轮说过什么了。
好消息是,差不多第14轮的时候,DeepSeek-V4自己也记不得了。
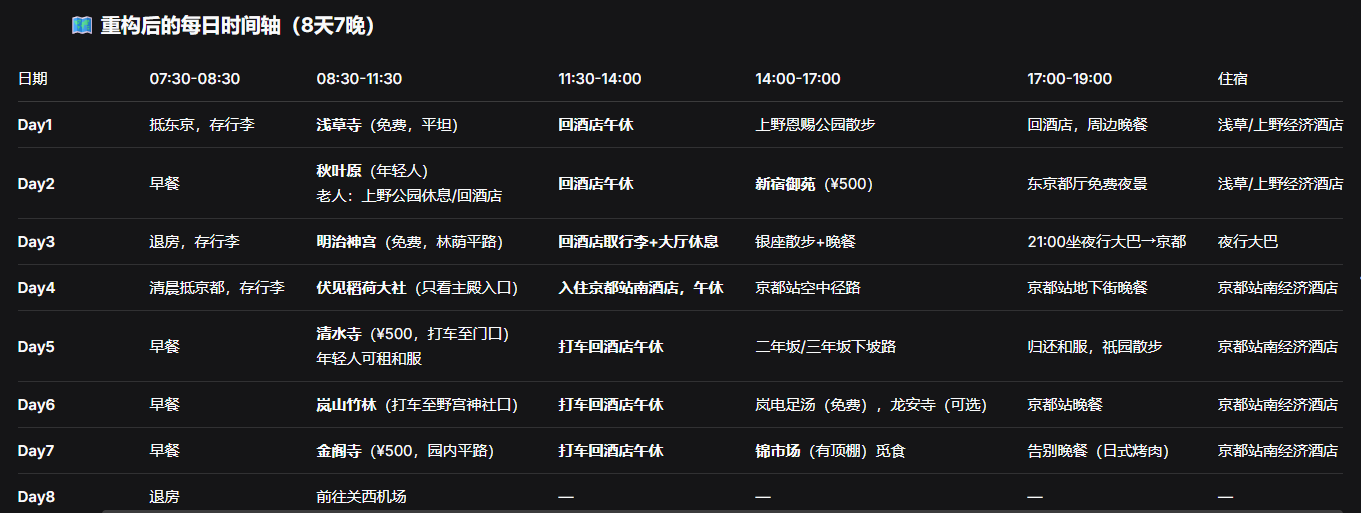
从第14轮开始,它规划的旅行安排就和之前交互中生成的那份安排没啥关系了。
甚至出现了第13轮还在规划箱根之旅,第14轮就在没有任何提示的情况下给它剔除了的喜剧效果。
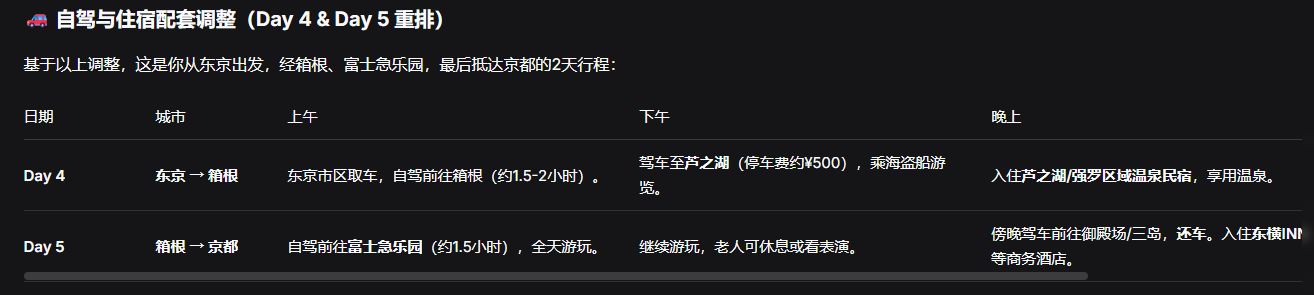
虽然对比之前DeepSeek的低专注度,现在的DeepSeek-V4能在高强度交互下保持一定的一致性,已经算是有所进步了,但是和我自己常用于角色扮演体验的Gemini-2.5-Pro依然存在明显差距。
总结:便宜好用才是硬道理
这一套连招测试下来,DeepSeek-V4给小雷的真实感受就是,它是一个很务实、干活利索,但稍微缺乏一点艺术细胞的模型。
它的优点非常突出,百万级别的长文本处理能力,不错的编程规划与执行能力,再加上不高的调用成本,这玩意和今年的龙虾潮非常适配,花一箱饮料的钱就能帮团队快速干完一星期的活。
而且最让国人提气的是,在外部技术环境如此复杂的情况下,他们大量依靠华为昇腾等国产芯片,跑出了比肩世界最强闭源模型的能力,这确实证明了国产算力生态正在迅速崛起。

当然,它的缺点也客观存在。它现在还没法像竞争对手那样直接看图或者看视频,在处理复杂的逻辑推理时偶尔会犯迷糊,而且写出来的视觉界面确实不太符合现代人的审美。
官方说它和顶级的闭源模型还有几个月的差距,这个评价非常中肯。
综合来看,DeepSeek这次交出的答卷是完全超出预期的,它不仅稳稳守住了国内开源模型第一梯队的位置,还有望把高高在上的算力价格给打下来。
对于咱们普通用户来说,现在的DeepSeek-V4绝对是一个日常工作、写代码、查资料的绝佳免费助手。至于多模态那些更高级别的功能,不妨给他们一点时间,让我们一起期待它下一次的进化。
本文来自转载雷科技 ,不代表发现AI立场,如若转载,请联系原作者;如有侵权,请联系编辑删除。