1. 开场白与课程概述
本段总结: 介绍了构建大语言模型的五个核心要素(架构、训练算法、数据、评估、系统)。讲者指出,虽然学术界痴迷于模型架构,但在实际工业界中,数据、评估和系统工程才是决定模型成败的关键。
大家好,今天我们将探讨如何构建大语言模型(LLMs)。简单回顾一下,LLMs 指的是大家最近常听到的那些聊天机器人,比如 OpenAI 的 ChatGPT、Anthropic 的 Claude、Google 的 Gemini 以及 Meta 的 Llama。今天,我们将揭秘它们到底是如何运作的。
在训练 LLM 时,有五个关键组件至关重要:
架构(Architecture):LLM 是神经网络,你需要决定使用什么架构。目前大家都在使用 Transformer 或其变体。
训练损失与算法(Training Loss & Algorithm):你将如何训练这些模型。
数据(Data):这是你用来训练模型的素材。
评估(Evaluation):你如何知道模型是否在朝着目标取得进展。
系统(Systems):在现代硬件上高效运行这些庞大模型的方法。现在的系统层面比以往任何时候都重要。

大多数学术界的研究(包括我职业生涯的大部分时间)都集中在架构和训练算法上,我们总喜欢发明新架构。但老实说,在实践中真正起决定性作用的是另外三项:数据、评估和系统。这也是工业界投入最多精力的地方。因此,今天我不会过多讨论 Transformer 的架构细节,而是重点讲解其他更重要的部分。
本次讲座分为两大部分:预训练(Pre-training)——经典的语言建模阶段,目标是让模型学习整个互联网的知识;以及后训练(Post-training)——ChatGPT 诞生以来的新范式,目标是将这些语言模型转化为真正的人工智能助手。
2. 预训练与自回归语言模型
本段总结: 预训练的核心任务是“自回归语言建模”,即通过概率分布预测序列中的下一个词。模型通过交叉熵损失函数进行训练,这等同于最大化文本的对数似然度。
首先,什么是语言模型?在宏观层面上,语言模型就是一个关于单词或 Token 序列的概率分布模型。具体来说,它建立了一个分布$P(X_1 … X_L)$。例如,对于句子“老鼠吃了奶酪”,语言模型会评估这句话在人类对话或互联网上出现的概率。如果句子存在语法错误,或者语义不通(比如“奶酪吃了老鼠”),模型赋予它的概率就会非常低。
因为语言模型掌握了概率分布,我们可以从中进行采样,从而生成新的数据,这就是为什么它们被称为生成式模型(Generative Models)。
目前大家使用的都是自回归语言模型(Autoregressive Language Models)。它的核心思想是利用概率的链式法则,将整个句子的分布拆解为:第一个词的概率,乘以给定第一个词后第二个词的概率,依此类推。它的任务非常简单:预测下一个词。
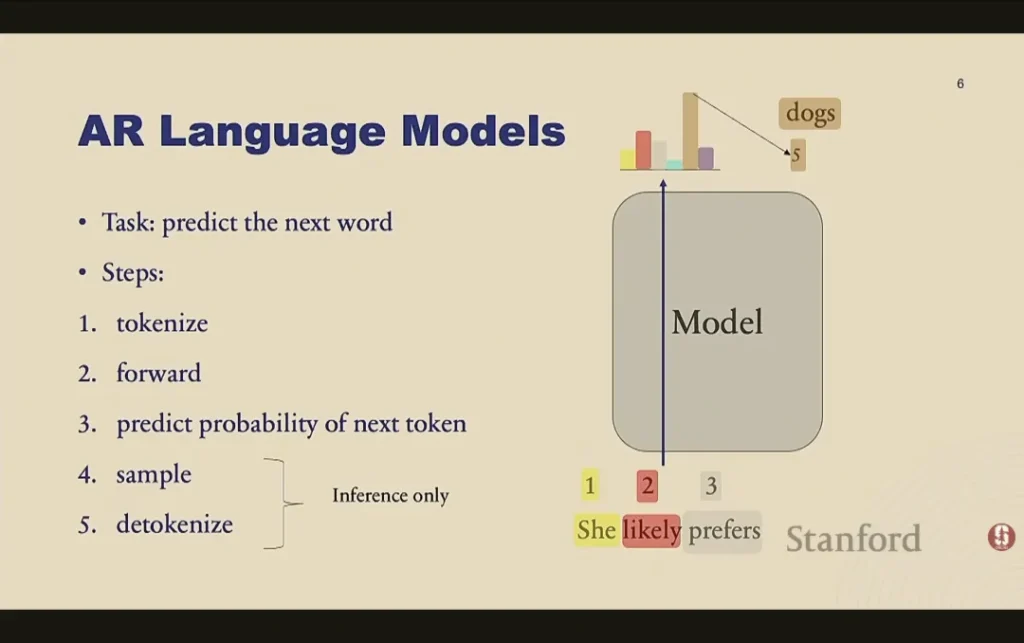
在训练时,我们会把序列中的每个词嵌入(Embed)为向量,通过 Transformer 网络获取上下文表征,再通过一个线性层映射到词表大小的维度,最后用 Softmax 输出下一个词的概率分布。我们使用的训练损失是交叉熵损失(Cross-Entropy Loss),这本质上是一个预测下一个 Token 的分类任务。在数学上,最小化交叉熵损失,完全等价于最大化文本的对数似然度(Maximum Likelihood)。

3. 为什么需要分词器(Tokenizer)?
本段总结: 详细解释了分词器存在的必要性,以及字节对编码(BPE)的工作原理。分词器解决了词汇表过大和拼写错误的问题,但也带来了诸如数学计算和代码缩进理解等局限性。
很多人往往忽视了分词器(Tokenizer),但它极其重要。我们为什么不直接用“单词”或“字符”作为基本单位呢?
如果用单词:遇到拼写错误的词汇(如 Typo),模型会遇到未登录词问题,且对于泰语等没有明显空格分词的语言很不友好。
如果用字符:虽然通用,但会导致序列极长。要知道,Transformer 的计算复杂度随序列长度呈平方级增长(二次方复杂度),序列太长会导致算力崩溃。
分词器提供了一个折中方案,通常一个 Token 包含 3 到 4 个字母。目前最流行的方法之一是字节对编码(BPE, Byte Pair Encoding)。
BPE 的训练过程如下:首先将大型语料库中的所有内容拆分为单个字符,然后统计相邻字符对的出现频率。找到最常见的字符对(比如“t”和“o”),将它们合并为一个新的 Token(“to”),并赋予唯一的 ID。不断重复这个合并过程,直到达到预设的词表大小。

不过,业界越来越意识到分词器的局限性。比如在处理数学问题时,数字往往被切分成奇怪的 Token,导致模型看待数字的方式与人类完全不同,影响了推理能力。此外,代码中的空格缩进(如 Python 的 4 个空格)过去也经常被分词器错误处理,这是 GPT-4 专门重构代码分词逻辑的原因。理想情况下,未来我们希望能摆脱分词器,直接处理字符或字节。
4. 评估指标:困惑度与学术基准
本段总结: 评估语言模型的传统方法是困惑度(Perplexity),而现在学术界更倾向于使用 MMLU 等客观题基准测试。同时,评测标准的不一致和训练集污染是目前面临的重大挑战。
我们如何评估模型?在开发阶段,最常用的是困惑度(Perplexity)。
困惑度本质上是验证集损失的一种可解释转化。公式是$2$的“平均每个 Token 的损失”次方。它的直观含义是:模型在生成下一个词时,正在几个词之间犹豫不决?如果模型完美预测,困惑度为 1;如果模型完全在瞎猜,困惑度就等于词表大小。在 2017 年到 2023 年间,标准数据集上的困惑度从 70 骤降到了 10 以下,进步惊人。
然而,困惑度在横向对比不同模型时存在问题(比如 Gemini 和 ChatGPT 的词表大小不同,困惑度就无法直接比较)。因此,目前的学术基准测试(如 Helm 或 Hugging Face 闭源排行榜)通常聚合大量的 NLP 任务。
最典型的是MMLU(大规模多任务语言理解),包含了大学物理、医学等多个领域的单选题。评估方式有两种:一是计算模型生成 A、B、C、D 四个选项的对数似然度,看正确选项的概率是否最高;二是直接限制模型输出,看它生成的下一个 Token 是不是正确答案。
评估面临的巨大挑战:
评估方式不一致:不同的 Prompt 或评分脚本会导致结果天差地别。比如 Llama 65B 在不同的测试平台上,准确率能从 48.8% 飙升到 63.7%。
训练集污染(Contamination):你的测试题是否已经被混入训练集了?为了检测污染,研究人员有时会故意打乱测试题的选项顺序,如果模型依然按原顺序生成答案,说明它很可能在训练时背过这道题。
5. 预训练数据:从“脏数据”到高质量语料
本段总结: 揭露了工业界处理预训练数据的艰辛过程。通过爬取 Common Crawl、HTML 文本提取、去重、启发式过滤和模型分类,最终留下高质量的、配比合理的数据集进行训练。
大家常说“用整个互联网的数据训练模型”,这听起来很简单,但互联网其实是一个“垃圾场”。Common Crawl 作为一个主流的开源爬虫项目,包含了大约 2500 亿个网页,数据量高达 1 Petabyte。如果你随机点开一个爬取的网页,里面全是不完整的句子和杂乱的代码。
为了清洗这些数据,需要一个巨大的工程流水线:
HTML 文本提取:去除网页代码,提取纯文本,同时还要处理棘手的数学公式提取和网页头部/底部的模板内容(Boilerplate)。
过滤不良内容:剔除 NSFW(不适宜工作场所)、有害内容和 PII(个人身份信息)。
去重(De-duplication):剔除重复的论坛签名或在全网被复制粘贴了上万次的段落。
启发式过滤(Heuristic Filtering):基于规则删除低质量文本。比如检查 Token 的分布是否异常,单词长度是否诡异,或者网页是不是只有 3 个词。
模型分类过滤:这是一个非常聪明的技巧。研究人员会提取维基百科中引用的所有外部链接,训练一个轻量级的分类器。然后用这个分类器扫描全网数据,保留那些“风格类似于维基百科引用来源”的高质量网页。
领域划分与配比:将数据分为代码、书籍、娱乐等。通常会增加代码(据称能提升推理能力)和书籍的权重,降低娱乐内容的权重。
退火(Annealing):在预训练的最后阶段,降低学习率,并在维基百科等极高质量的数据上“过拟合”,以提升模型最终的表现。
在业界,处理数据所需的 CPU 算力和团队规模,有时甚至超过了研究架构本身的投入。Llama 3 训练使用了高达 15 万亿个 Token。高质量数据是绝对的核心商业机密。
6. 缩放定律(Scaling Laws)与资源分配
本段总结: 缩放定律证明了模型性能与算力、数据量、参数量成可预测的对数线性关系。这彻底改变了模型研发流程,让研究人员可以通过训练小模型来精准预测大模型的表现。
在传统机器学习课上,我们总是担心“过拟合”。但在大型语言模型中,过拟合几乎不存在:数据越多,模型越大,性能就越好。
更神奇的是,这种提升是可以精确预测的。OpenAI 发现,如果把算力(Compute)、数据集大小或参数量放在对数坐标的 X 轴上,把测试损失(Test Loss)放在 Y 轴上,它们呈现出完美的线性关系。
这彻底改变了研发管线(Pipeline):
以前,如果你有 10000 张 GPU,你可能会训练 30 个不同超参数的大模型,每个训练 1 天,挑出最好的。
现在,你会利用几张 GPU 训练一系列不同规模的“小模型”,拟合出一条 Scaling Law 曲线。然后,你可以极其自信地预测出那个 1000 亿参数的终极模型如果训练 30 天会达到什么水平,并直接把所有算力押注在那个终极模型上。
那么,有限算力下,是该增加参数量,还是增加数据量?
DeepMind 的 Chinchilla 论文给出了答案。通过绘制不同算力预算下的等高线图(Iso-flops),他们发现计算最优解是:每增加 1 个参数,就应该增加 20 个训练 Token。
但在工业界实践中,由于要考虑模型部署后的推理成本(Inference Cost),公司更倾向于训练相对较小的模型,但在海量数据上进行超额训练。所以目前的比例通常是 150 个 Token 对应 1 个参数(如 Llama 3)。
7. 训练成本与碳排放的“信封背面计算”
本段总结: 通过基础数学公式估算了 Llama 3 400B 模型的训练成本,展示了前沿 AI 研发巨大的资金和算力门槛,以及在当前阶段可控的碳排放规模。
让我们用 Llama 3 400B 模型做个粗略的计算。它有 450 亿(此处讲者口误,应指 Llama 3 的大参数量版本计算)参数,训练了 15.6 万亿 Token。
所需算力(Flops):计算公式大致为$C = 6 \times P \times N$(其中$P$为参数量,$N$为数据量)。计算结果约为$3.8 \times 10^{25}$Flops。拜登政府的行政命令要求算力超过$10^{26}$Flops 的模型需要接受特殊审查,Meta 恰好卡在这个红线之下。
训练时间:使用 16000 张 H100 显卡,结合其吞吐量,大约需要持续训练 70 天,耗费近 2600 万 GPU 小时。
训练成本:假设 H100 的租金下限为每小时 2 美元,单纯的显卡成本就超过 5200 万美元。算上顶尖研究员的薪水(约 50 人,年薪 50 万美元起),总成本至少在 7500 万美元左右。
碳排放:大约排放 4000 吨二氧化碳当量,相当于从纽约到伦敦的 2000 趟往返航班。目前来看,碳排放在整个大环境里还算可控,但如果算力再提升 100 倍,这就会成为一个真正的环境问题。
8. 后训练:将模型转化为 AI 助手(SFT)
本段总结: 预训练模型只会续写文本。为了让它听从指令,必须使用监督微调(SFT)机制。研究表明,SFT 的关键在于格式对齐,而不需要大量数据。
预训练阶段得到的只是一个“语言模拟器”。如果你给 GPT-3 纯预训练模型输入“请向一个 6 岁的小孩解释登月”,它可能会续写出“请向一个 6 岁的小孩解释引力”,因为它在模仿互联网论坛的提问模式。
要把它变成 AI 助手,我们需要进行对齐(Alignment),也就是后训练(Post-training)。
第一步是监督微调(SFT, Supervised Fine-Tuning)。我们收集人类写好的高质量“问答对”,在这个数据集上继续用语言模型的目标(预测下一个词)来微调模型。因为人类编写数据极其昂贵,现在流行用最强的 LLM(如 GPT-4)来生成合成数据(Synthetic Data)进行微调,比如我们之前做的 Alpaca 模型就是这样做的。
令人惊讶的是,Lima 论文指出,SFT 并不需要海量数据(几千条足矣),从 2000 条增加到 32000 条并没有带来本质提升。原因在于:预训练已经把所有的知识塞进了模型里,SFT 的作用仅仅是教模型“如何格式化地输出你期望的答案”,而不是教它新知识。
9. RLHF 与 DPO 偏好优化
本段总结: 仅靠 SFT 会导致幻觉和人类能力天花板问题。通过引入强化学习人类反馈(RLHF)或直接偏好优化(DPO),模型可以直接优化人类的偏好,产生更优质的输出。
仅仅做 SFT 有几个致命缺陷:
人类能力上限:SFT 属于行为克隆(Behavioral Cloning)。但我评价一本书的好坏,比我自己写一本书要容易得多。如果只模仿人类生成的内容,模型永远无法超越人类专家的写作水平。
幻觉(Hallucinations):如果人类在 SFT 数据里提供了一个冷门知识点,而这个知识点模型在预训练时完全没见过,模型就会学会“一本正经地胡说八道”,强行生成看似合理的错误答案。
为了解决这个问题,我们需要引入偏好优化。核心流程是:给定一个指令,让模型生成两个不同的答案,让人类标注员(或强大的 LLM)来选择哪个更好(比如绿色优先于红色)。
算法 1:RLHF(强化学习人类反馈)配合 PPO 算法
这是 ChatGPT 最初突破的关键。首先用偏好数据训练一个奖励模型(Reward Model),将离散的偏好转化为连续的打分(Logits)。然后用 PPO(近端策略优化)这种强化学习算法,将 LLM 作为一个智能体(Agent)进行训练,以最大化奖励得分为目标。
但这极度复杂!强化学习极度不稳定,包含了无数的裁剪(Clipping)和工程 Trick,连写出 PPO 的原作者都觉得难以完美复现。
算法 2:DPO(直接偏好优化)
斯坦福去年提出的一种优雅替代方案,现已成为开源界的主流。既然我们的目标是“多生成喜欢的,少生成不喜欢的”,为什么不直接在数学上把它转化为一个最大似然估计问题呢?
DPO 直接将偏好数据带入损失函数,最大化人类偏好答案的概率,惩罚被拒绝答案的概率。它彻底抛弃了奖励模型和强化学习,仅仅用交叉熵的变体就达到了与 PPO 同样的甚至更好的效果。
10. 评估后训练模型:LLM 裁判的崛起
本段总结: 评估对齐后的模型非常困难。目前业界依赖于“聊天机器人竞技场”进行盲测,为了降低成本,大量使用 LLM 作为裁判(如 Alpaca Eval)来自动化评估。
经过 RLHF 之后,模型已经不再是一个标准的概率分布模型了(它在努力让最优解的概率逼近 1),所以困惑度(Perplexity)在这里失效了。而且,开放式回答没有标准答案。
目前最权威的评估方式是Chatbot Arena(聊天机器人竞技场),这是一种盲测系统,让人类在两个匿名模型中投票。
但让人类投票太慢且太贵,所以业界开发了基于 LLM 的自动化评估(比如 Alpaca Eval)。你只需要给 GPT-4 两个回答,问它哪个好。我们发现,LLM 的评判与人类投票的拟合度高达 98%,成本却便宜了 50 倍。
警惕虚假相关性(Spurious Correlation):
LLM 裁判(和人类一样)存在严重的**“偏好较长输出”(Length Bias)**。如果在 Prompt 里要求模型“啰嗦一点”,它的胜率会莫名其妙飙升至 64%;如果要求“简明扼要”,胜率会跌穿 20%。这是对齐训练中需要通过因果推断等统计手段去消除的顽疾。
11. 系统基础知识与显卡优化
本段总结: 计算系统的优化直接决定了训练的成败。因为 GPU 的内存通信带宽常常是瓶颈,业界广泛采用低精度训练(16 位)和算子融合技术来大幅提高算力利用率。
对于开发 LLM 的任何人来说,算力永远是瓶颈。简单地“买更多 GPU”是行不通的,因为通信开销会拖垮多卡互联系统。
如果你想理解系统级优化,记住一点:CPU 优化的是延迟(Latency),而 GPU 优化的是吞吐量(Throughput)。GPU 天生为极速的矩阵乘法而生。
但目前 GPU 最大的瓶颈在于:算力提升的速度远大于内存通信带宽提升的速度。很多时候,由于数据无法及时从显存(HBM)传输到计算核心(SMs),你的 GPU 大部分时间都在闲置。在工业界,模型浮点运算利用率(MFU)能达到 50% 就已经是极其出色的成绩了。
两个关键优化技巧:
低精度 / 混合精度训练:在深度学习中,小数点后几位并不关键。我们将庞大的矩阵乘法运算放在 16 位精度下进行,以成倍减少显存占用和通信带宽;只在存储模型权重和执行参数更新时,保留 32 位精度以确保学习率生效。
算子融合(Operator Fusion):如果你在 PyTorch 里写一行简单的连续运算(比如求 Cosine 再求 Sine),传统方法是将数据从显存搬运到计算核心,算完搬回去,再搬出来算下一步,这是极其浪费的。使用torch.compile,系统会自动将代码在底层重写为 C++ (CUDA) 的融合算子,把所有数据一次性送入核心,全部算完再取回,这能让模型训练速度直接翻倍。
这就是从架构、数据到系统的 LLM 构建全貌,希望对大家有所启发。
本文来自转载The AI Frontier ,不代表发现AI立场,如若转载,请联系原作者;如有侵权,请联系编辑删除。