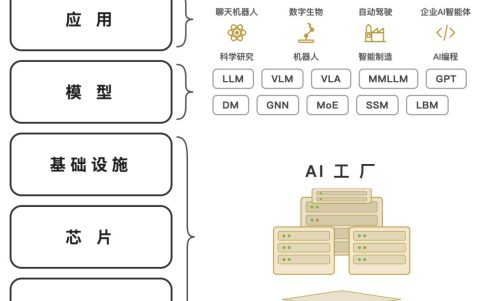
2026年是Agent(智能体)真正普及的一年。随之而来的是,Token(词元)浪费也正在成为技术和学术领域被广泛讨论的新问题。
今年4月,小米MiMo大模型负责人罗福莉在社交媒体X(Twitter前身)上发布了一条动态,讨论现在OpenClaw“龙虾”等Agent工具低效的问题。她认为,全球算力供给,正无法跟上Agent带来的Token需求增长。
罗福莉解释了这背后的原因——OpenClaw这类Agent工具每次用户对话,都会发起多轮低价值的工具调用。每一轮都作为独立API(应用接口)请求发送,并产生一个很长的上下文(通常超过10万Token)。即便有缓存命中,这种方式依然非常浪费。极端情况下,还会提高其他请求的缓存失效率。
Token浪费(在技术社区、论文平台中被称为Token Waste),并非单个产品的问题。它是Agent能力提升过程中的必经之路。
《财经》统计了全球最大的代码和开源技术社区GitHub上有关“Token Waste”相关Issues(问题,可理解成技术议题讨论)的数量。这一讨论至少有5200个,仅2026年一季度就诞生了4150个。越来越多的开发者在实际业务中正面临控制Token浪费的问题。
《财经》统计了全球最大预印本论文平台arXiv(计算机等领域的科研人员习惯在此上传论文初稿)上“Token Waste”相关论文。2025年1月以来,这个主题直接或间接相关的论文至少有92篇,且2026年一季度就诞生38篇。学术界也越来越关注Token浪费成因以及如何减少Token浪费这一课题。
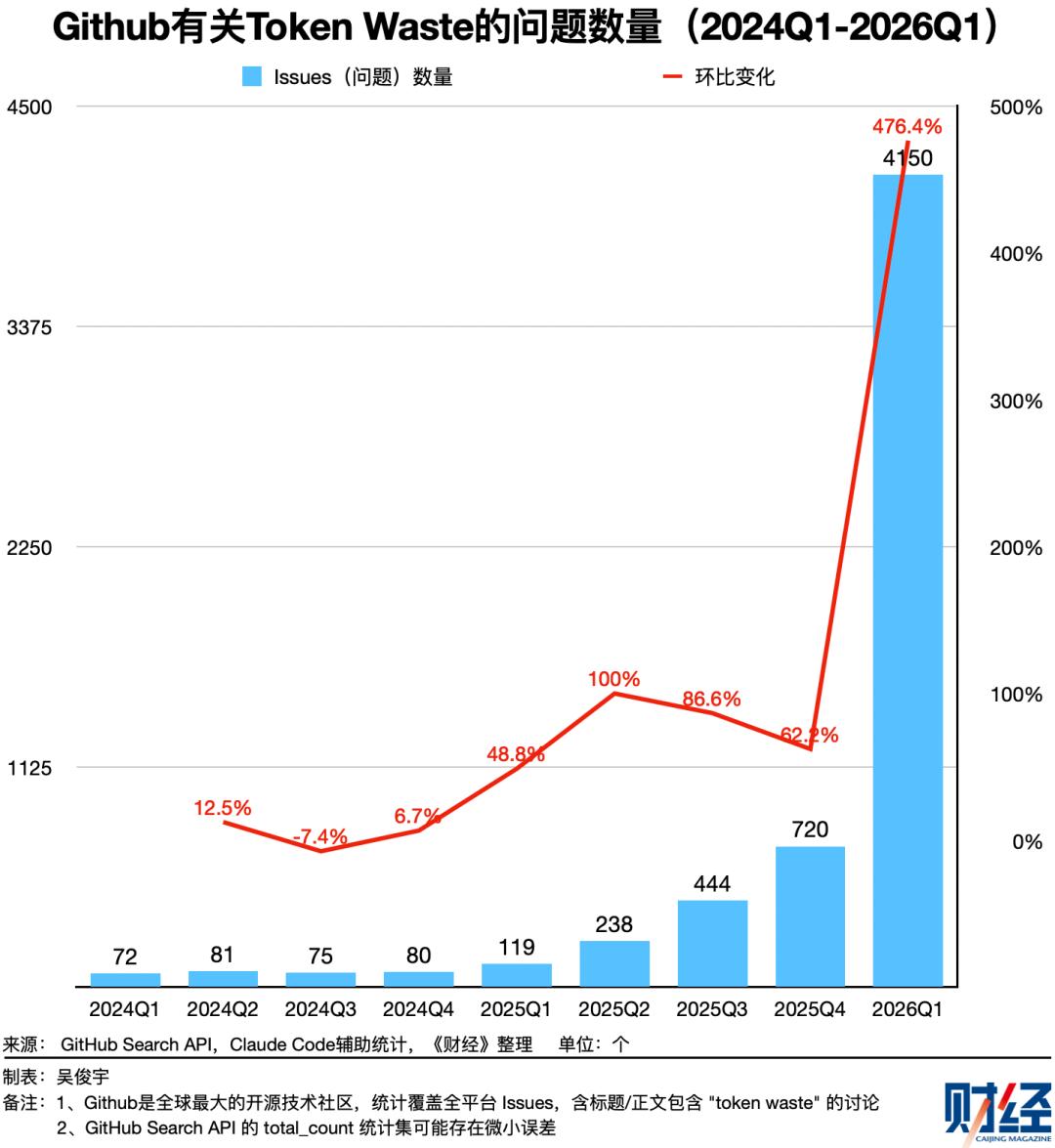
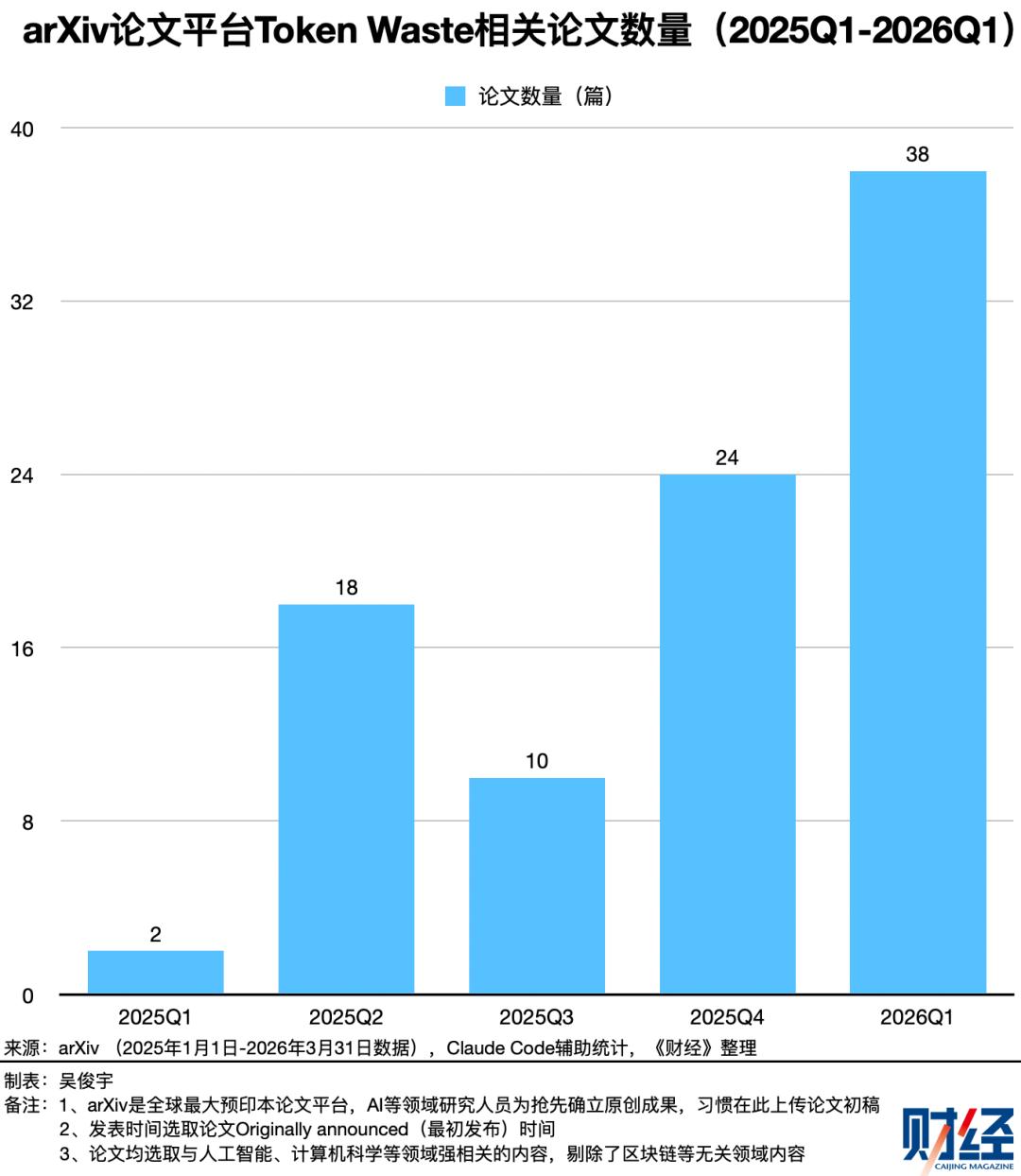
开发者和研究者的常见观点是——Agent在复杂多轮任务中,历史文件、对话会不断累积,大量无用、冗余、过期的信息会不断产生并且重复计算。Token消耗因此指数级增长,但其中可能有30%-60%的Token被浪费了。
Token浪费的商业影响是,虽然算力消耗的飞轮转动起来了,但上下游的良性商业循环仍未建立。上游的模型公司(如美国市场的OpenAI、Anthropic,中国市场的月之暗面、MiniMax、智谱)、应用公司(如全球最大的独立AI代码生成平台Cursor)营收在增长,却仍在亏损。下游开发者和企业用户的Token账单不断膨胀且难以精确预估。
不过,多位企业开发者和算法工程师对《财经》表示,无需因Token浪费而悲观。事实上,企业、开发者都在尝试为Agent加上更好的“脚手架”——通过优化Agent框架等方式减少Token浪费。
因为在技术发展早期,没有浪费就没有进步。Token浪费才会推动试错,Agent会在技术进化和市场选择中不断成熟。
01
Token是如何被浪费的?
Agent目前框架还不够成熟,Token很容易被浪费。
当下的Agent,简单理解,就像一匹尚未被完全驯服的“野马”。这匹“野马”执行任务时四处飞奔,不一定会按照人的意志朝着最短路径行走——Token消耗有时候会偏离最优解。
它很多时候不知道哪些问题与当前任务直接相关,于是只能把所有文件都读一遍。随着对话轮次增长,上下文不断积累,缓存的计算任务不断膨胀。用户每次输入后,Agent甚至可能需要重新计算完整的对话记录和文件数据。这导致Token成本指数级增长。
Agent工具的Token消耗量远超过去的AI对话工具。百度智能云大模型平台总经理忻舟2025年12月曾对《财经》表示,Agent系统执行的是一系列任务。任务过程中,模型会不断用代码规划任务、调用工具并记录执行状态,每个步骤都可能触发新的模型调用。一次对话可能只消耗数千Token,但一次任务可能就会消耗数万,甚至数十万Token。
今年3月,一位名为shelvenzhou的开发者在Github进行了一项基准测试,记录自己的OpenClaw日常工作(包括代码、邮件、PDF、图片、搜索等)Token消耗情况——第一轮对话Token成本0.0050美元;第五轮对话Token成本0.0665美元,是第一轮的13.3倍;第10轮的Token成本达到了0.13美元,是第一轮的26倍。
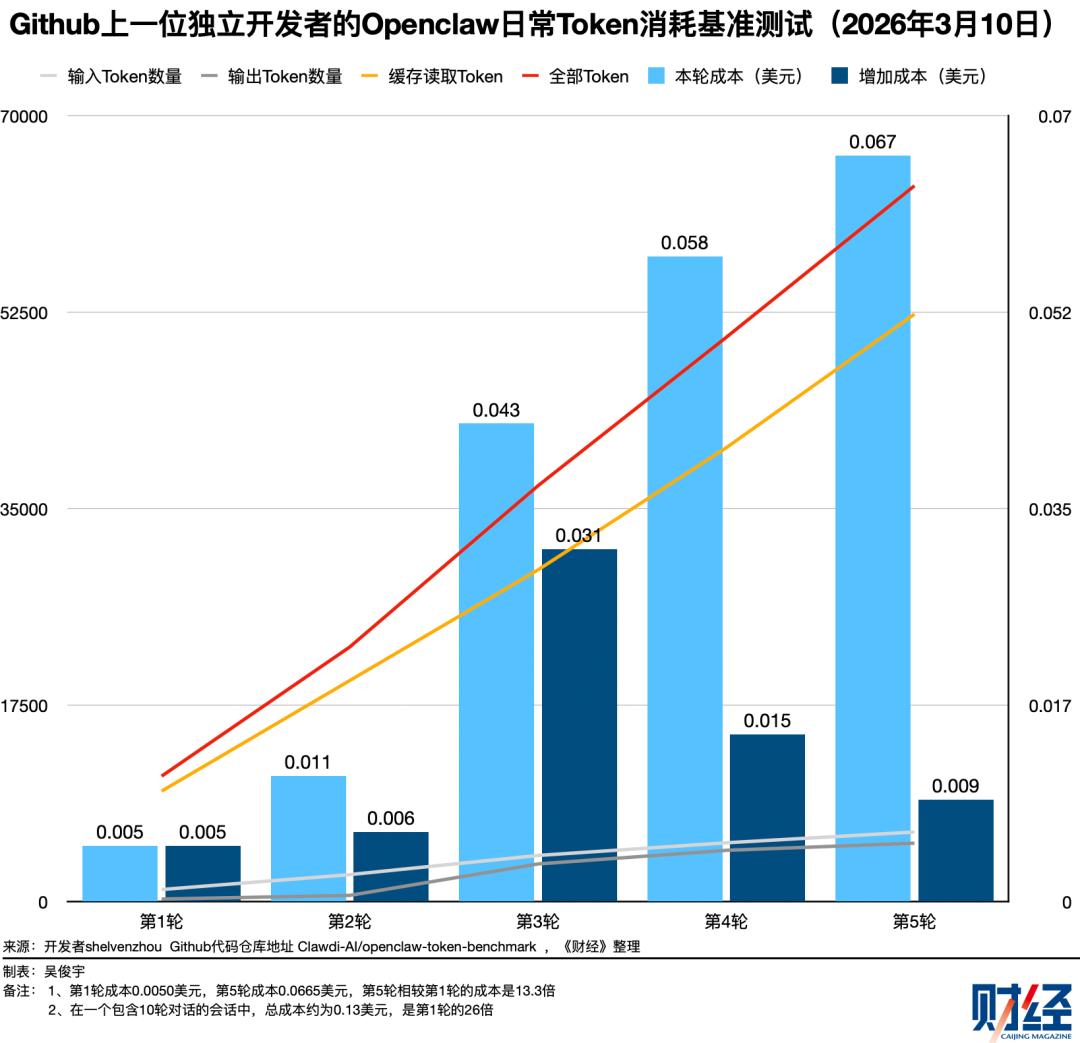
类似情况在《财经》团队的工作流中同样存在。今年3月,《财经》尝试用全球热门的独立AI代码生成平台Cursor统计财报数据——阅读20份亚马逊财报PDF文件,统计最近20个季度亚马逊AWS的营收、利润并绘表。
Cursor使用OpenAI的GPT-5.3-Codex模型自动运行近30分钟。任务并没有一次性成功。Cursor逐一尝试了四种路径,每次任务失败后再寻找新路径并自动编写新代码,历经十多轮最终完成统计。整个过程花费了130万Token,占20美元/月Token用量约5%。但人工复核后发现,个别季度统计仍然出错了——这次任务虽然完成了,但结果不可用。
这次失败的财报统计任务,耗费了近30分钟和7元Token费用。那么,这130万Token是如何被消耗掉的?
实际任务中,1个中文字符约等于0.6个Token,1个英文字符约等于0.3个Token。亚马逊一份季度财报通常50页,超过10万字符,对应约3万Token。
一位算法工程师对《财经》表示,Cursor不会把20份PDF文档从头到尾全部读完,而是根据任务提取PDF文档中的关键句子并理解,随后自动编写任务代码,把所有季度的数据进行汇总。编写代码的过程也消耗Token。在Agent多轮调用过程中,由于上下文反复传递以及多种路径尝试,Token消耗被进一步放大,最终达到130万Token以上的量级。
这种个人办公任务还不算复杂,但在企业生产系统,任务执行时间更长、更复杂。这会变成持续性的Token成本。
今年3月末,Lumigo&Vexp联合创始人尼古拉·阿莱西(Nicola Alessi)在技术社区记录了自己的编程 Agent一周Token消耗情况。他认为,其中70%的Token被浪费了。
他的代码Agent使用了Claude Sonnet 4.6模型,被用于一个拥有超过200个文件的严肃生产场景。他强调,这不是普通的试验项目。
尼古拉·阿莱西长期监测发现,平均每次提问,Agent会发起23次工具调用——先扫描全部文件,再按编程语言过滤一遍代码,随后逐一打开文件、读取内容,如此循环超过20轮,才终于开始处理实际问题。这20轮循环中,每次对话平均消耗约18万个Token,其中与问题真正相关的Token,不超过5万个。
按照这一数据计算,Token浪费率高达72%。以Claude Sonnet 4.6定价计算,每次对话平均浪费的Token费用在1美元左右。单次对话浪费的Token看似只有约1美元,但在大规模部署和持续高频调用下,这会逐渐累积成巨额算力支出。
因为员工规模动辄数万甚至数十万的大型科技公司,尤其在技术部门,工程师的每月Token费用甚至已在万元以上。做好成本优化,每年可节省千万元级别的算力成本。
一家员工数超过30万人的国际科技巨头人士对《财经》表示,他所在的公司每个人使用的Token是无限量的。他的工程师同事长期使用Claude系列的模型编写代码,一周Token成本高达2000美元-3000美元。
一家员工数超过10万人的中国科技公司技术人士对《财经》表示,他在云基础设施部门,日常使用Claude Opus 4.6模型写代码,每周Token成本高达3000元。
一家员工数5万人左右的互联网硬件公司人士对《财经》表示,他所在公司已经为全员配备Agent办公或AI代码生成工具。他们有自研模型,因此员工使用Token不限额度。在他看来,Agent造成的Token浪费几乎是见怪不怪。他在日常办公中有30%-50%的Token由于Agent工程不够完善被浪费了。
02
谁在为浪费的Token买单?
Agent造成的浪费让Token消耗量变得难以预测。这甚至在影响整个市场的蛋糕分配。
从技术来看,Token浪费是Agent框架不成熟导致的。但从产业结构来看,它更像是技术发展早期的成本传导——“算力-模型-应用”之间的蛋糕还没分好,成本不断向下游传导,这些Token成本最终是由企业客户承担的。
过去数字化转型阶段(2024年之前),市场蛋糕划分相对清晰。云厂商提供算力资源,SaaS(应用软件)公司提供软件产品,企业客户按需采购,三者边界清晰、角色分明。当时,企业IT成本相对可预测。企业可以根据业务规模规划云资源,还能和云厂商签订长约获得折扣。软件是订阅制的,按年/月订阅座席付费,成本相对固定。
2025年之后,AI落地速度加快,蛋糕逐渐变得划分不均。云厂商分走了大部分收入与利润,模型厂商收入快速增长却仍普遍在亏损,SaaS公司转售Token有“管道化”的趋势。
产业链最末端的企业CTO(首席技术官)/CIO(首席信息官)面对的不再是云和软件订阅账单,而是一种类似流量管控和动态限速的混合计费账单。Token账单变得难以预测。
其一,Agent任务执行过程本身Token消耗波动就很大。不同Agent框架成熟度不同,Token消耗量差异也很大。
今年4月,一款名为Hermes的Agent迅速流行,它在开发者社区口碑迅速超过OpenClaw。Hermes会将经验自动生成Skill(技能),减少反复低效试错,Token消耗相对更少。4月12日,一位开发者在Reddit社区记录称,他用OpenClaw和Hermes处理同一任务,OpenClaw 10分钟消耗200多万Token,Hermes仅消耗50万Token。
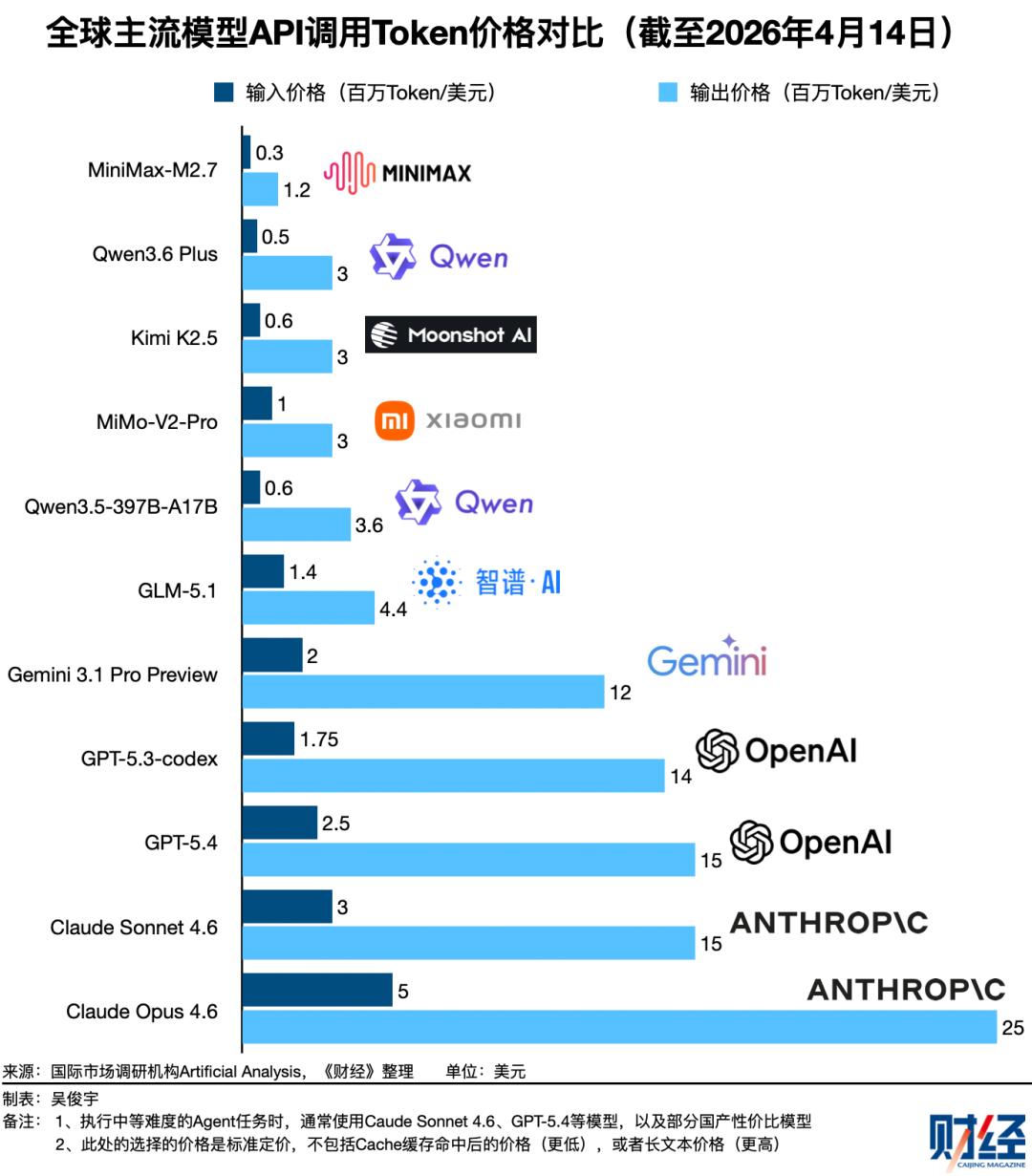
其二,不同模型之间,性能与定价差异明显。即使性能相近,Token定价差距仍然显著,这让成本评估变得更复杂。
目前在开发者口碑最好的Claude Sonnet 4.6、GPT-5.4的Token定价普遍是国产模型的3倍-10倍。国产同级别模型,Token定价差距也在1倍-3倍之间。如何根据合适的场景选择合适的模型,这对企业来说决策成本很高。
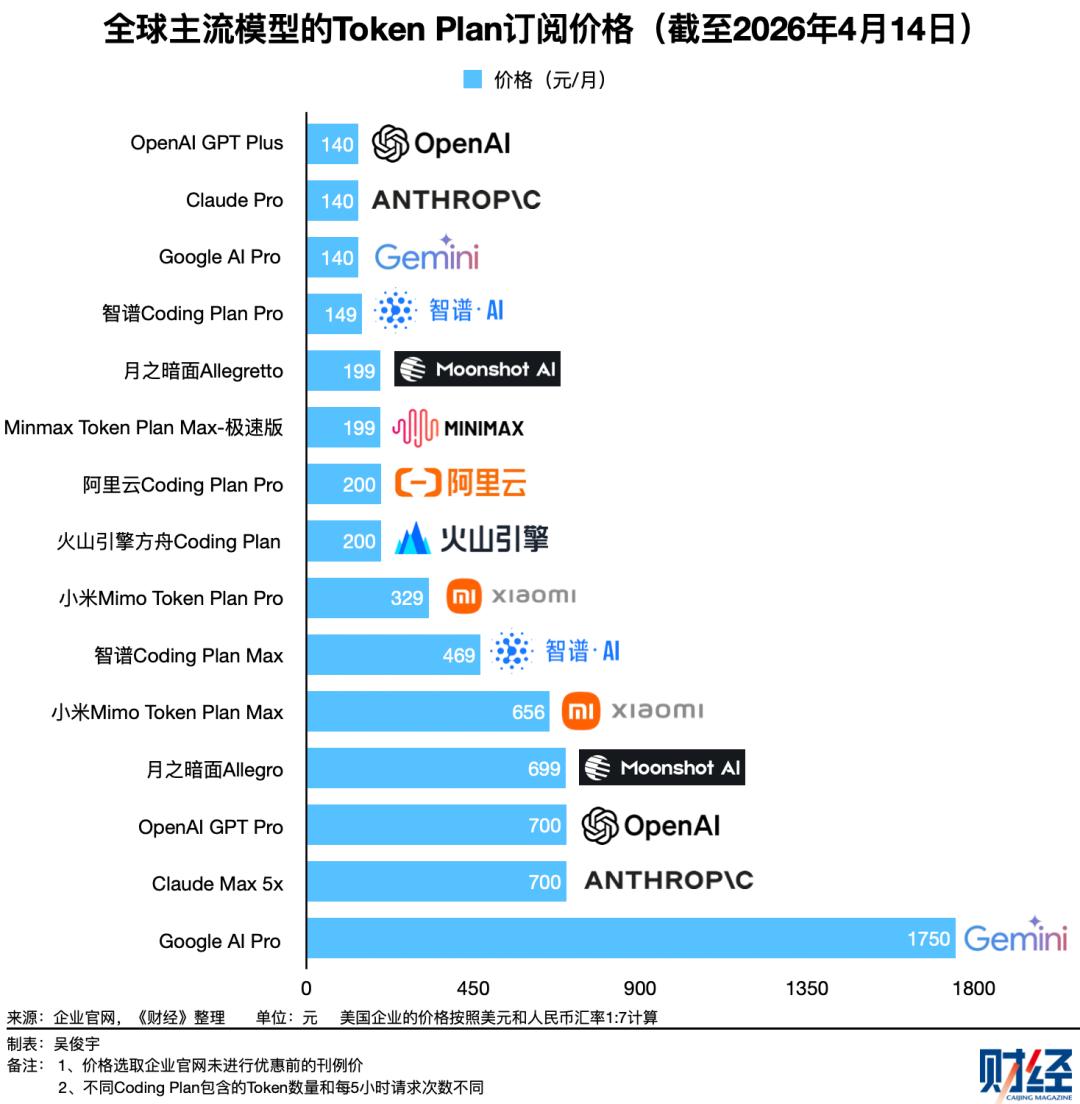
其三,Token套餐(Coding Plan或Token Plan)虽然看似价格固定,但套餐内的Token额度、并发数量、缓存计费规则差异明显。套餐用尽后的超额费用、降级策略也各不相同。企业很难在纸面上提前对比评估真实成本。
目前大多数Token套餐以5小时为刷新周期,限制用户时间窗口内的最大调用次数或最大Token额度。一旦5小时内使用超额,系统会触发限速、排队或降低模型性能等机制。这个机制原本是为了尽量公平分配算力资源,却让企业提前算账变得更难了。
这一系列问题让企业的IT预算编制变得困难。《财经》了解到的情况是,一些头部零售、制造企业为解决这个问题,正在尝试独立编制专门的Token预算。
一位服务了多家头部零售、制造企业的企业级大模型服务商CEO(首席执行官)今年3月对《财经》表示,企业普遍在AI焦虑期。这些Token预算正在吃掉传统软件、外包开发的预算。不过,目前很难精确计算Token预算的ROI(投资回报率)。
企业客户正在付出更高的Token成本,这带动了模型厂商、应用厂商收入的快速增长。然而作为供给方,模型厂商、应用厂商并没有想象中那么赚钱。
美国和中国的模型创业公司普遍在亏损。在美国市场,OpenAI 2026年2月ARR(年度经常性收入,当月收入×12)超过250亿美元,预计2030年盈利。Anthropic 2026年3月ARR超过300亿美元,预计最早将在2029年盈利。
在中国市场,月之暗面2026年2月收入超过2025全年,到2026年3月ARR甚至超过1亿美元。MiniMax 2025年营收0.79亿美元(约合5.6亿元),2026年2月ARR超过1.5亿美元(约合10.5亿元)。智谱2025年营收7.2亿元,2026年3月模型API(应用接口)的ARR达到17亿元,同比增长60倍。
不过,这三家公司也在亏损。月之暗面的亏损规模尚未披露。MiniMax 2025年经调整后的净亏损2.5亿美元(约合17.5亿元),智谱2025年经调整后的净亏损31.8亿元。
新兴的AI应用公司普遍在亏损,甚至成了封装Token的管道——接入模型公司的API(应用接口),将Token转售给客户。软件原本的定价权转移到了云厂商和模型公司手里。
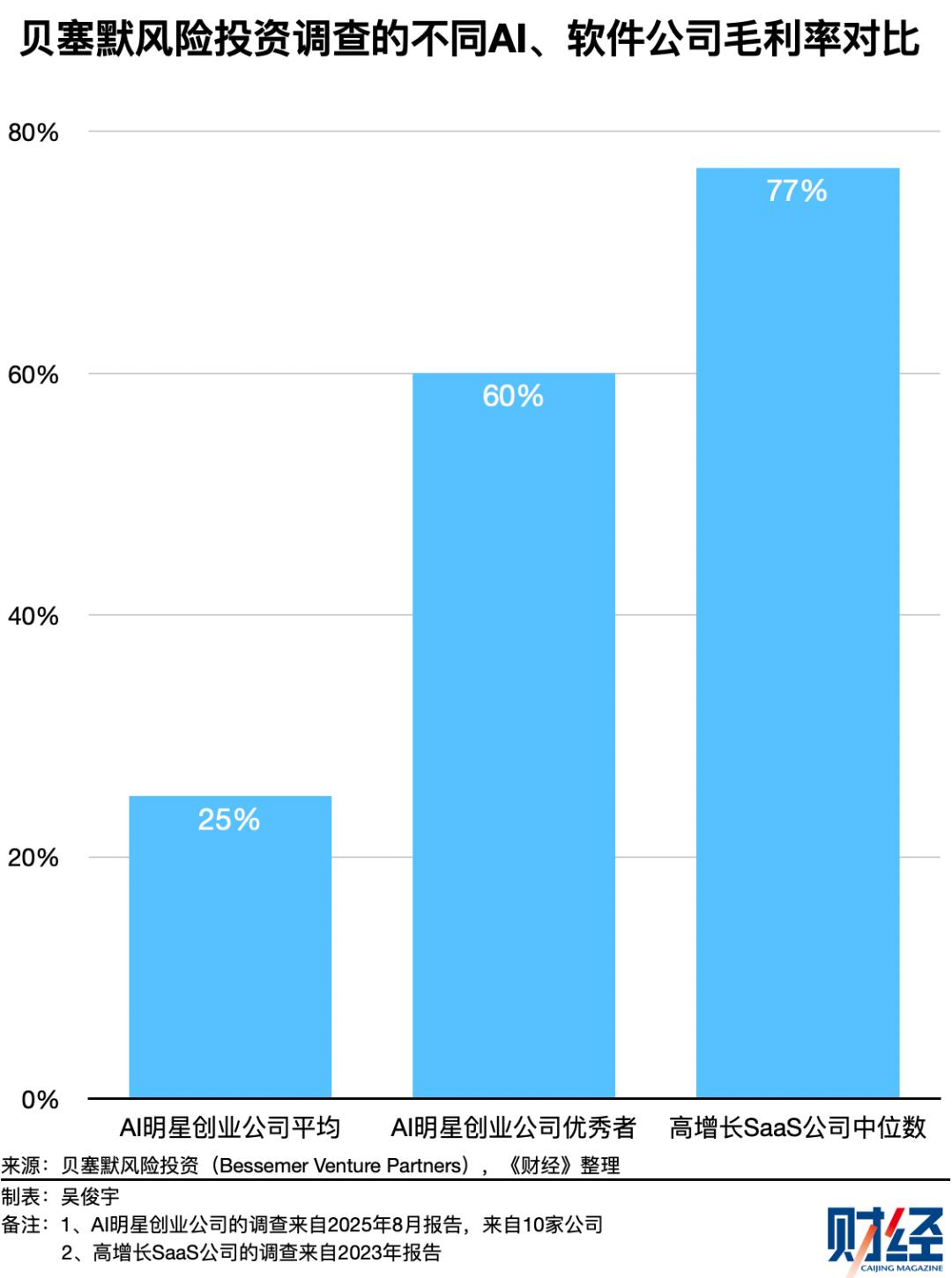
美国知名投资机构贝塞默风险投资(Bessemer Venture Partners)长期聚焦SaaS和AI赛道。贝塞默风险投资2025年调查10家AI明星创业公司发现,这些公司平均毛利率仅为25%,部分表现优秀的公司平均毛利率约为60%。
但根据贝塞默风险投资2023年调查结果,高增长SaaS公司毛利率中位数约为77%。也就是说,AI应用相比过去的SaaS软件,毛利率正大幅下滑。
最典型案例是,全球最大的独立AI代码生成工具Cursor。它在2026年2月年化收入超过20亿美元。但美国市场调研机构AI Funding Tracker 2026年2月报告称,Cursor 2025年亏损规模至少在1.5亿美元。Cursor几乎所有收入都被用于调用Anthropic、OpenAI的模型。公司还要支付员工工资、办公场所等其他运营费用。
全球最大的SaaS公司,如Salesforce、Adobe、ServiceNow这几家老牌公司同样在面临AI相关毛利率下降的问题。SaaS软件毛利率长期在80%左右,一直被认为是高毛利的好生意。但现在情况正在变化。
Salesforce管理层2025年12月公开表示,在Agent业务快速扩张阶段,公司短期内可以接受这部分业务的利润率承受压力。
Adobe管理层在2026财年一季度财报电话会(2026年3月12日)表示,Firefly和 Express这两款生成式AI应用会带来更高的Token成本,并可能会影响公司利润率。
ServiceNow管理层在2025年四季度财报电话会(2026年1月28日)表示,预计2026年订阅毛利率为82%,将略微下滑。AI相关的算力投入是影响毛利率的主要来源。
综上所述,Token消耗虽然在增长,但目前至少在模型公司、应用公司、企业客户这里都还没有真正形成正循环。这些成本在层层传导的产业链中被不断放大和转移。
03
如何从Token浪费中榨出利润?
减少Token浪费,本质上是在为“算力-模型-应用-企业客户”整个产业链减少无效成本,进而释放出利润空间。只有这样,“Token经济”的飞轮才能真正转起来。
当前减少Token浪费的主流技术方案包括两大类:一是KV Cache(Key-Value Cache,键值缓存),二是Agent工程。
KV Cache是什么?简单理解,这是模型对已计算上下文的结果进行缓存,避免生成新Token时重复计算整个上下文。这正在成为模型公司榨取利润空间的关键技术。
今年4月,一位中国大模型创业公司人士对《财经》表示,他们销售的Token套餐本身几乎不赚钱,利润空间主要来自KV Cache的命中率。换句话说,KV Cache命中得越多,模型厂商的实际计算成本就越低,利润空间也就越大。
OpenAI的开发者技术文档显示,OpenAI通过KV缓存输入Token成本最高下降90%。一位云计算厂商智能算法负责人2025年12月曾对《财经》表示,利用KV缓存等技术,他们能够把推理成本降至10%-20%。
Agent工程,也就是把Agent的调度、记忆、模型路由、上下文裁剪和工作流管理做成一套可控的系统工程。它的目的是,减少Agent不必要的重复计算、工具调用、思考推理和空转循环。这在今天也被称为Harness——这个词字面意义上是缰绳和马具。
这是云厂商、模型公司、应用公司都在优化的方向。腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生今年4月发表文章称,人工智能正式进入Harness时代。Harness是缰绳,它将(大模型)这股原始力量转化为可控的、可预期的、可协作的能力……驯服一匹野马,需要一副趁手的缰绳,和一个知道目的地的骑手。
汤道生发现,在腾讯内部,在同样的模型能力下,不同的脚手架设计,比如给模型调用什么工具、如何做分层的上下文工程、如何管理长记忆、如何设计工作流,对实际使用效果与Token成本有很大的影响。
Agent工程成熟与否,直接决定了同一项任务的Token消耗量——这将直接影响企业的Token成本。
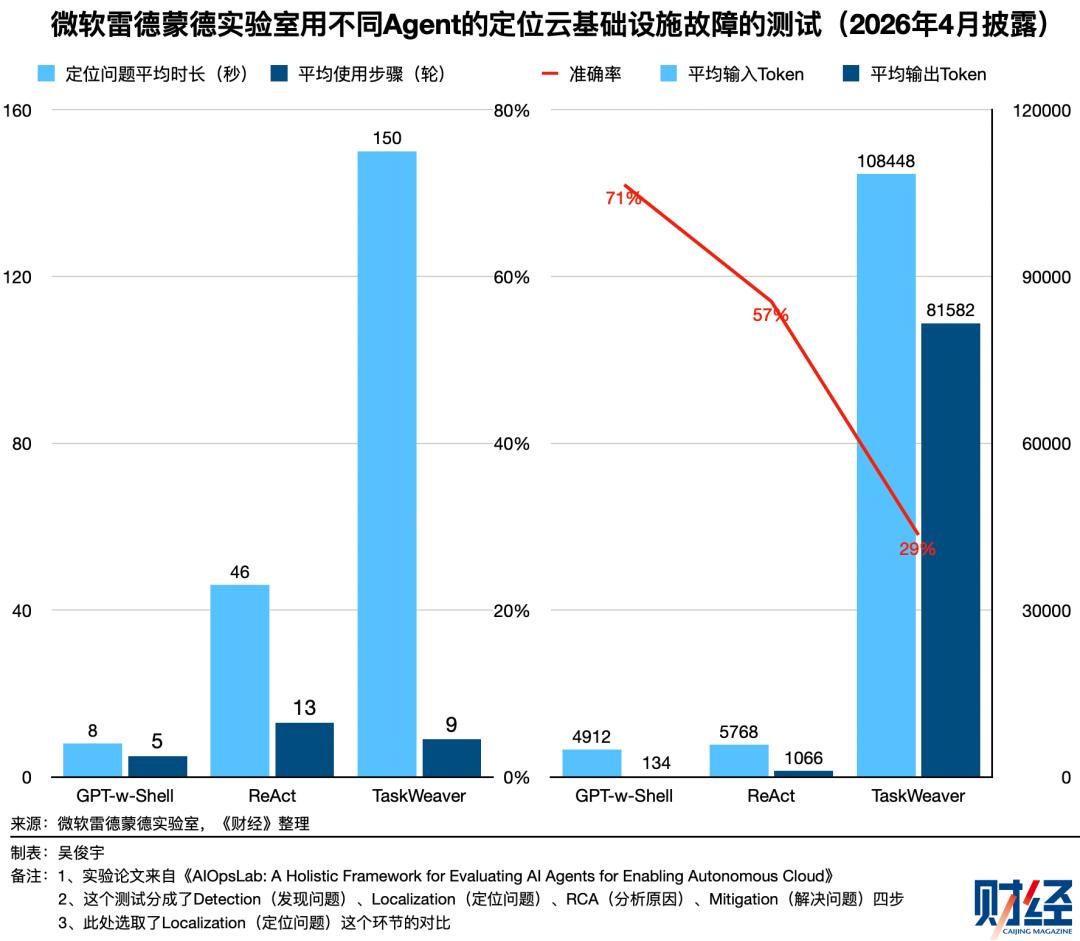
微软雷德蒙德实验室今年4月披露了一个利用不同Agent对云基础设施进行自动故障处理的案例。在使用同一模型定位故障问题这个环节,不同Agent的Token消耗差距明显。表现最好的GPT-w-Shell,在71%正确率下仅消耗约5000个Token;ReAct在57%正确率的情况下消耗了6800个Token。TaskWeaver正确率仅29%,Token消耗高达19万。
2026年初,浙江大学计算机辅助设计与图形学国家重点实验室研究团队向ICLR(国际学习表征会议,机器学习领域三大国际顶级会议之一)提交了一篇名为《Stop Wasting Your Tokens》(停止浪费你的Token)的论文。
该研究团队提出,通过在Agent系统中引入一个“监督Agent”,可以在不改变模型结构的前提下,实时识别错误、低效行为与冗余上下文,减少无效计算。实验结果显示,这个方法在保持任务成功率的同时,将Token消耗平均降低了30%。
微软的工程实践、浙江大学的试验,这些都处于控制Token浪费的早期。这些经验随着技术成熟,将逐渐落地到更多公司。
未来一段时间,谁能用更少的Token完成同样的任务,谁就会拥有更高的利润空间。也会拥有更加确定的未来。
上述互联网硬件公司人士对《财经》表示,无需因Token浪费而悲观。这是Agent现在这个发展必然经历的过程。他所在的公司目前有大量精力投入到Agent工程,这不单是为了节省Token成本,也为了提升任务准确率。在当下,提效远比降本重要。
2010年以后移动互联网起步,流量浪费和流量焦虑一度让用户关心,但在今天已经无人关注这些问题。Token浪费情况类似。Token浪费推动了试错,试错推动了优化,优化最终会推动“算力-模型-应用-企业客户”整个产业链走向成熟。
“Token经济”的正向循环也将在这个过程中逐渐形成。
本文来自转载半熟财经 ,不代表发现AI立场,如若转载,请联系原作者;如有侵权,请联系编辑删除。