一个好名字,就是一个超级符号,是无形资产。
对于个人,对于品牌、商标是这样,对于新兴事物层出不穷的大时代更是如此。
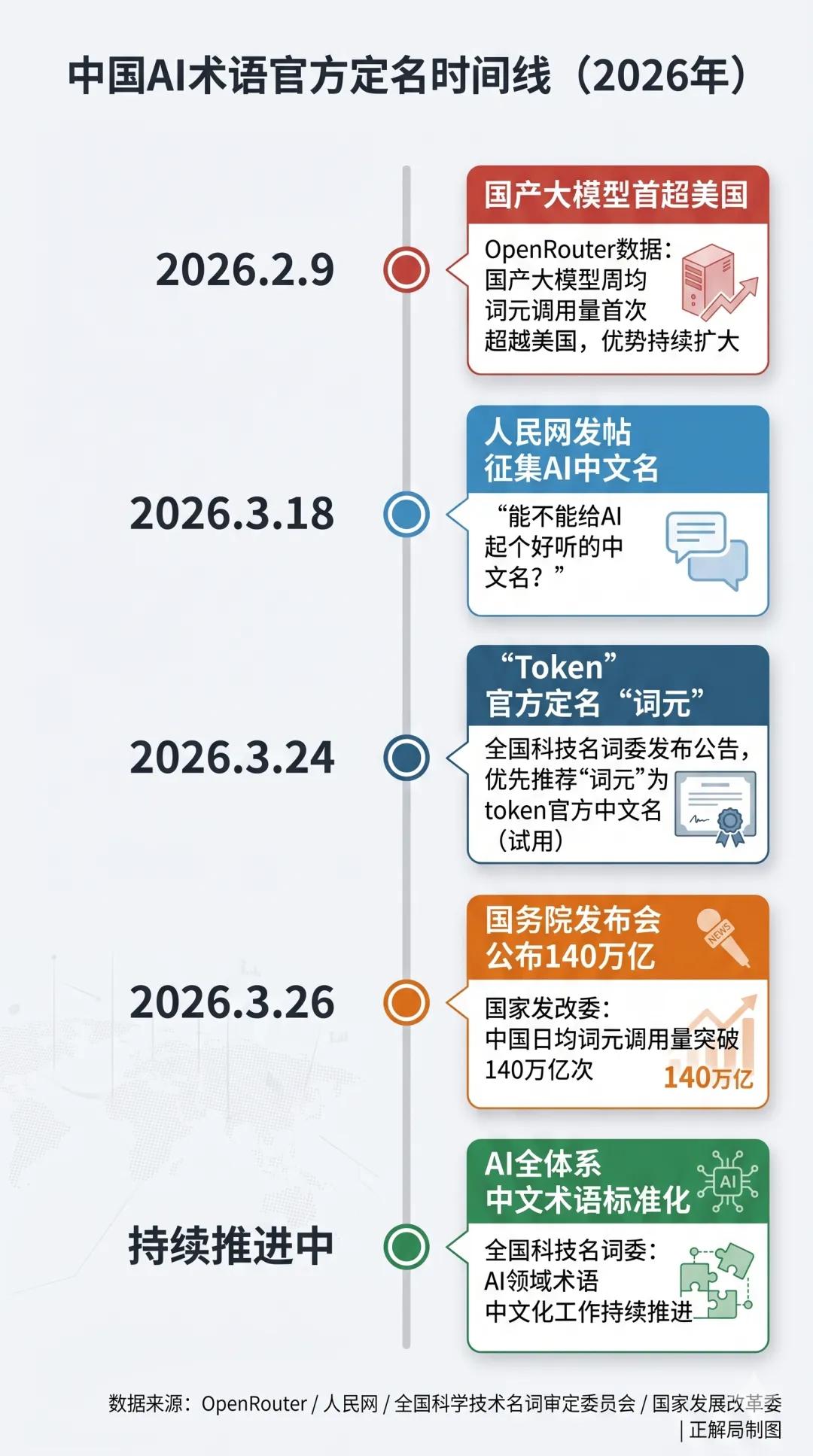
前段时间,人民网发英雄帖征集意见:“请给AI起个好名?”
语气诚恳,甚至有点着急:
AI发展迅猛,直接照搬字母、没有汉字的用法,显得直白粗陋,也不符合国家通用语言文字规范;虽然有“人工智能”这个叫法,但似乎缺少形象感与亲和力,还有机会再顺口一点。
随后,官方在中国发展高层论坛年会上,使用“词元”指代人工智能领域中的“Token”。
消息一出,有人叫好,觉得终于有了“自己的词”;也有人觉得多此一举,“Token叫习惯了,何必折腾?”
事实上,这件事绝不是咬文嚼字那么简单。
这是一场关于叙事主权的争夺,而叙事主权,是这个时代最隐秘、也最重要的战场。
中国AI术语官方定名时间线(2026年3月)
词语,是比芯片更底层的权力
100年来,美国最成功的发明创造是什么?
是原子弹、航天飞机吗?是计算机、芯片吗?
不,是一个词语,叫做“美国梦”(American Dream)。
1931年,正是大萧条时期,美国作家亚当斯在《美国史诗》一书中创造了“美国梦”一词:
“在这片土地上,每个人都应该过上更美好、更富足、更圆满的生活,能依靠自己的能力挣到自己想要的一切……
美国梦不只是汽车,也不只是高工资,而是一种社会秩序,在这种秩序下,所有男人和女人都能凭借自身素质取得最大成就,并得到社会承认,而与他们的出身、社会背景和社会地位无关。”
这个词太好了!
给了所有人来到这片北美新大陆拼搏攀爬的希望,而不论出身。
很快,这个词成了漂亮的“包装纸”。
民权运动领袖马丁·路德·金用它凝聚各色人种的共识,里根总统拿它推进重大公共政策的落地,奥巴马用它当招牌,招揽新移民前来。
小布什则把美国梦定义为“拥有房产”,推动“零首付房贷”,直接引发了2008年金融危机。
有一款2007年发售的电子游戏《侠盗猎车手4》,主题也是一个欧洲非法移民来美国追求美国梦的故事。
对了,在游戏中,唐人街的路人会用粤语向主角说话,但大多都是唾骂主角的粗言秽语。
典型的西方叙事霸权!
不夸张地说,谁掌握了叙事,谁就掌握了经济的方向盘。
诺贝尔经济学奖得主罗伯特·席勒,在《叙事经济学》中写道:
“叙事是历史、文化、时代精神以及个体选择相结合的载体,甚至是一种集体共情。某种程度上,它解释或说明一个社会、一个时期的重要公共信念,而信念一旦形成,将潜移默化或者直接影响每个人的经济行为。”
席勒的结论是:叙事,是一个非常重要的经济变化机制,也是关键的预测变量。
这个道理,在科技界、商业界体现得淋漓尽致。
2021年,Facebook创始人扎克伯格宣布公司更名为“Meta”,并向全世界宣告:元宇宙(Metaverse)时代来了。
这个词,来自1992年的科幻小说《雪崩》。
现身巴黎凡尔赛门展览中心
扎克伯格把它挖出来,重新包装,然后砸了数百亿美元“建设元宇宙”。
全球科技公司闻风而动,“元宇宙”概念股一飞冲天。
但两年后,“元宇宙”概念凉了,苹果发布Vision Pro,刻意回避了这个词,改用了一个全新的概念——“空间计算”(Spatial Computing)。
这不是苹果的谦虚,是一次精心策划的叙事战略升级。
“元宇宙”让人联想到逃离现实、沉溺虚拟;“空间计算”则暗示这是一种更高级的、与现实融合的计算范式。
玩的是同一件事,换一个名字,用户的感知、市场的预期、资本的流向,全都变了。
什么叫词汇塑造世界观?
这就是西方精英厉害的地方——
他们不只是在造产品,他们很会造概念,造叙事。
当全世界都在用他们发明的词汇时,就是在无意识地接受他们的技术架构、商业逻辑和价值观。
说句不好听的,这是一种隐秘的语义殖民。
如果失去命名权?
语义殖民,不是比喻,是活生生的历史。
1835年,英国殖民者麦考利在印度起草了一份《印度教育备忘录》。
这份文件,后来演变成英属印度的法律,改变了整个印度次大陆的命运。
麦考利在备忘录里写道,他的目标是培养一个“肤色是印度人,但品位、道德和智力是英国人”的精英阶层。
手段很简单:用英语教育,取代本土语言教育。
这个政策,在印度执行了将近两百年。
对比来说,中文对科学术语的意译传统是汉字表意性的独特优势,让以汉语为母语的我们,可以通过构词直接理解概念。
来感受一个词:“光合作用”。
中国孩子一看,脑子里立刻有画面——光,合成,作用。
像是“光合作用”、“基因”、“细胞”、“显微镜”,还有钱学森首创的“导弹”、“航天”、“航宇”这些词……
天然就有特征,有画面感,我们就知道这是科学,而不是“西方专属的”科学。
但今天,英语强势绑定着印度几乎所有医学、法律、商业管理和理工学科。
而本土的印地语,还有各邦的语言方言,只能停留在日常生活和一些简单的基础教育上。
印度孩子要死记硬背“Photosynthesis”(光合作用),可就太难了,这对他们来说,是一串没有意义的字母。
语言分层,在印度就代表机会分层。
英语学得好,直接跑去硅谷做高管,成为跨国公司的合伙人;不懂英语的底层,只能做流水线上的“双手”,可能连村子都出不了。
在最前沿的科学技术上,印度这个国家,就很难建立起自己的叙事,拥有自己的技术标准,更难建立自己的话语体系。
像张雪这样的人,英语不好,不耽误在中国干出很牛的摩托车,在印度可就太难了!
日本的教训,则更接近当代。
二战后,日本大量引入西方科技词汇,用片假名直接音译(就像汉语拼音一样)。
电视机叫“テレビ”(Terebi),电脑叫“パソコン”(Pasokon),互联网叫“インターネット”(Intānetto)……
这些词,对日本年轻人来说还可能熟悉,但对老年人和普通民众来说,就是天书。
大量片假名加剧了日本社会的数字鸿沟,这太诡异了。
如果一个国家,连自己的语言都无法承载新技术,是多么可怕的一件事?
中国翻译史上的“神来之笔”
但凡学过中学历史的人,就不难理解:秦始皇“书同文”的意义,远大于“车同轨”。
郑州大学汉字文明研究中心主任李运富教授,在《汉字汉语论稿续编》中有一段精确表述:
汉字的超时空表意功能,让汉民族长期保有共同文化基础,巩固了民族意识稳定和国家统一;中国境内少数民族普遍采用汉字作为共同书面语,促进了各民族情感认同与文化沟通。
汉字克服了方言的隔阂,让广土众民的中国,保持了两千多年的文化统一性。
古往今来,每一项舶来的事物、概念,都会在中国的文化大熔炉中焕发新的生命力。
清末,严复翻译赫胥黎的《天演论》,把“Evolution”和“Natural Selection”翻译成“物竞天择,适者生存”。
这八个字,不是直译,而是用中国人最熟悉的语言逻辑,重新创造了一遍,也成了整个中国近代思想启蒙的底色。
这就是“信达雅”的力量,当年梁启超读到这本书,激动得彻夜难眠。
这样的传统到了信息时代,那更是大放异彩。
“Computer”,翻译成“电脑”。一下把计算机的核心特征说清楚了——用电运行、像大脑一样思考的机器。
“Mouse”,翻译成“鼠标”。一看就懂,有尾巴(线),会跑,像老鼠。
“Internet”,翻译成“互联网”。“互”字点出了双向连接的本质,“网”字勾勒出了整个架构的形态。
“Byte”,翻译成“字节”。形象生动地描述了“机器存储信息的最小单位”,当“字节跳动”起来,竟成就了全球价值最高的独角兽公司。
这哪是翻译?这是理解再发明!
正是因为这些科技词语被成功“中文化”,哪怕是没上过大学的包子铺大妈,也能毫无障碍地理解和拥抱互联网科技红利。
新技术的低门槛渗透,是中国能够在短短二十年内,从互联网的跟随者变成领跑者的重要原因之一。
AI这次不一样
今天人工智能带来的颠覆性意义,可能要超过工业革命以来,任何一次技术变革。
不同的是,这次中国站在前排,遥遥领先。
中国日均词元(Token)调用量增长曲线 数据来源:国家发展改革委/新华网
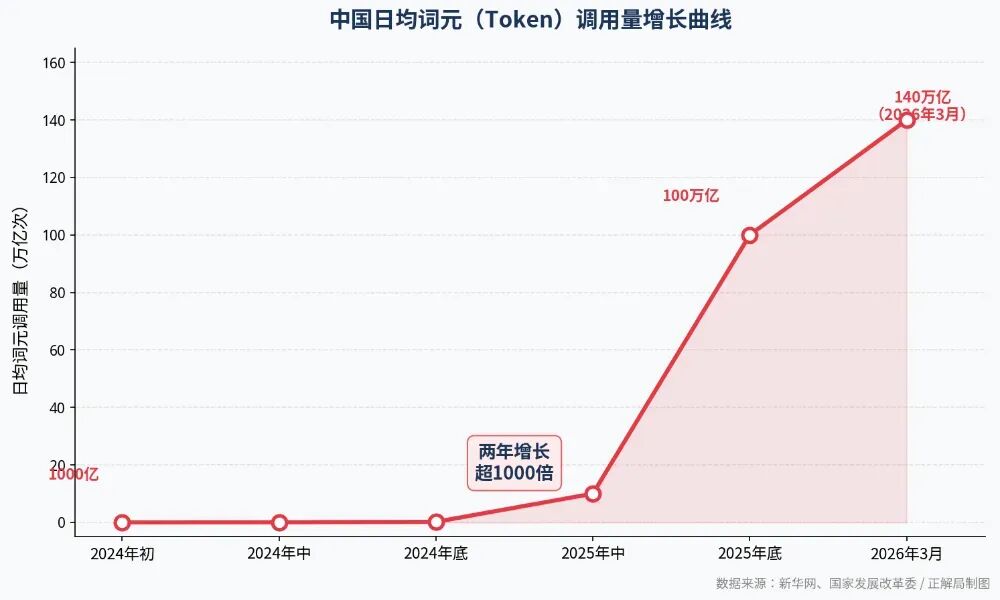
今年3月,官方公布:中国日均词元(Token)调用量,突破140万亿次。
这是全中国全口径、全场景所有AI大模型的总Token调用量,这个数字从2024年初的1000亿,两年增长了超过1000倍,相比2025年底的100万亿,短短三个月又增长了40%以上。
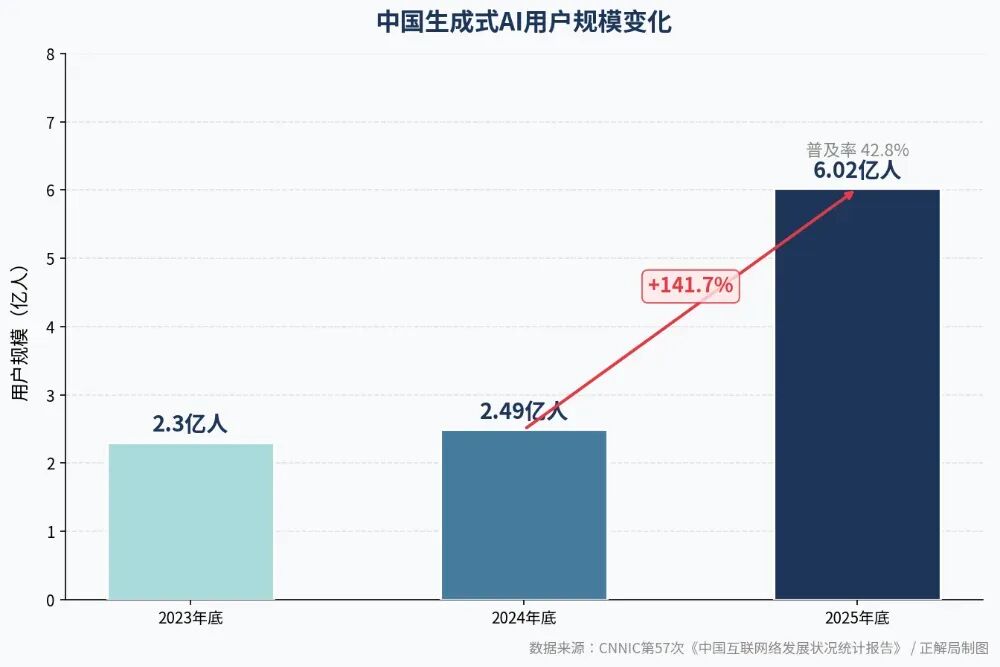
与此同时,中国互联网络信息中心的数据显示:
截至2025年12月,中国生成式AI用户规模达到6.02亿人,普及率42.8%,一年内增长了141.7%。
中国生成式AI用户规模(2024年底—2025年底) 数据来源:CNNIC第57次互联网发展状况统计报告
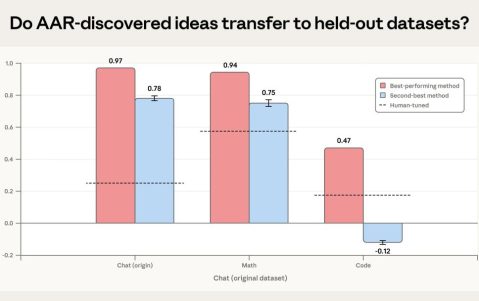
而全球最大的AI模型API聚合平台Open Router的数据显示,从2026年2月9日那周开始,在周均词元调用量这一核心指标上,国产大模型连续超越美国模型直到今天,并且优势还在持续扩大。
全球制造业大国身份还在,今天又成了词元制造大国。
AI正在以肉眼可见的速度,从科技圈的玩具,变成普通人的日常工具,渗透进工作生活的方方面面。
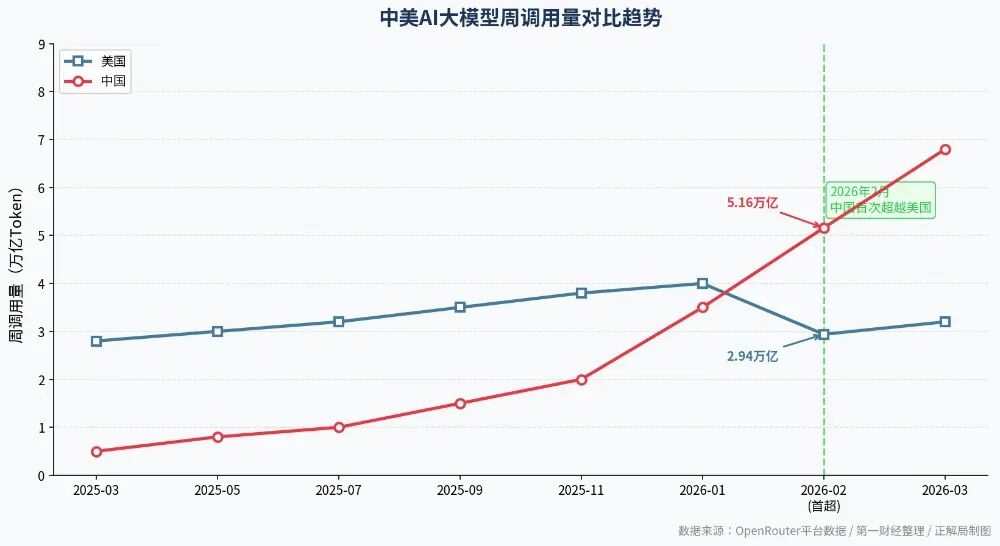
中美AI大模型周调用量对比趋势 数据来源:OpenRouter平台数据/第一财经整理
这个时候,假如AI的基础词汇全部沿用英文而没有中文名称,会发生什么?
教授、城市白领、乡镇干部,乃至初中没毕业的工人,在AI面前,他们遇到的都是“Token”(词元)、“Prompt”(提示词)、“Fine-tuning”(微调)、“Embedding”(嵌入)……
这些词,和印度孩子背“Photosynthesis”(光合作用)没有区别。
10多亿中国人会被挡在AI时代的门外。
这还只是问题的最表层。
更深层的逻辑可能是:谁定义了AI的技术语言,谁就定义了AI的方向。
在算力被“卡脖子”、芯片被制裁的今天,如果连描述AI的基础词汇都要跟别人借,那这种跟随,就从技术延伸到认知,最终变成战略上的跟随。
在英文语境里,“Token”带有“代币、信物”的商业意味,折射出西方科技公司将一切数据化、货币化的底层逻辑。
而中文定名“词元”,把重心放在“词”和“元”上——语言的基本单元,意义的最小粒子,回归技术本源。
这不同的味道,你细品?
背后是完全不同的技术哲学:AI的本质,不应是交易工具,而是语言理解的机器。
一个名字,代表两种世界观。
实力才是叙事的内核
其实呢,真正的叙事主权,从来不是靠起名字得来的。
在1890年代,世界上大多数语言都有了自己的打字机,都是根据拉丁字母打字机改造而来,泰国的暹罗文也能用打字机打出来,中文却不行。
从机械打字、编码打字、铅印、照排,再到激光照排、电脑打字,汉字进入信息化系统,用了100多年。
无数志士为此努力,连文人林语堂都在1947年,发明了一款72键盘的明快打字机。
当时的主旋律是追赶,是追求平权。
到了21世纪,“互联网”这个词之所以能够深入人心,也不是因为这个翻译有多精妙,而是因为中国干出了很牛的数字经济——腾讯、阿里、华为、字节跳动和随处可见的移动支付、短视频,让世界信服。
庞大的应用场景,为“互联网”一词注入了中国内涵。
AI时代,也是同样的逻辑。
叙事主权的建立,需要技术实力的支撑,更需要整个社会的参与。
科学家用中文写出影响世界的论文,工程师用中文定义影响行业的标准,企业家用中文讲出漂亮的商业故事。
而普通人,用中文学习最前沿的技术。
名字,是权力的外衣。
实力,才是叙事的内核。
一个词元,只是 一个开始。
本文来自转载微信公众号“正解局” ,不代表发现AI立场,如若转载,请联系原作者;如有侵权,请联系编辑删除。